
.svg)

TL;DR
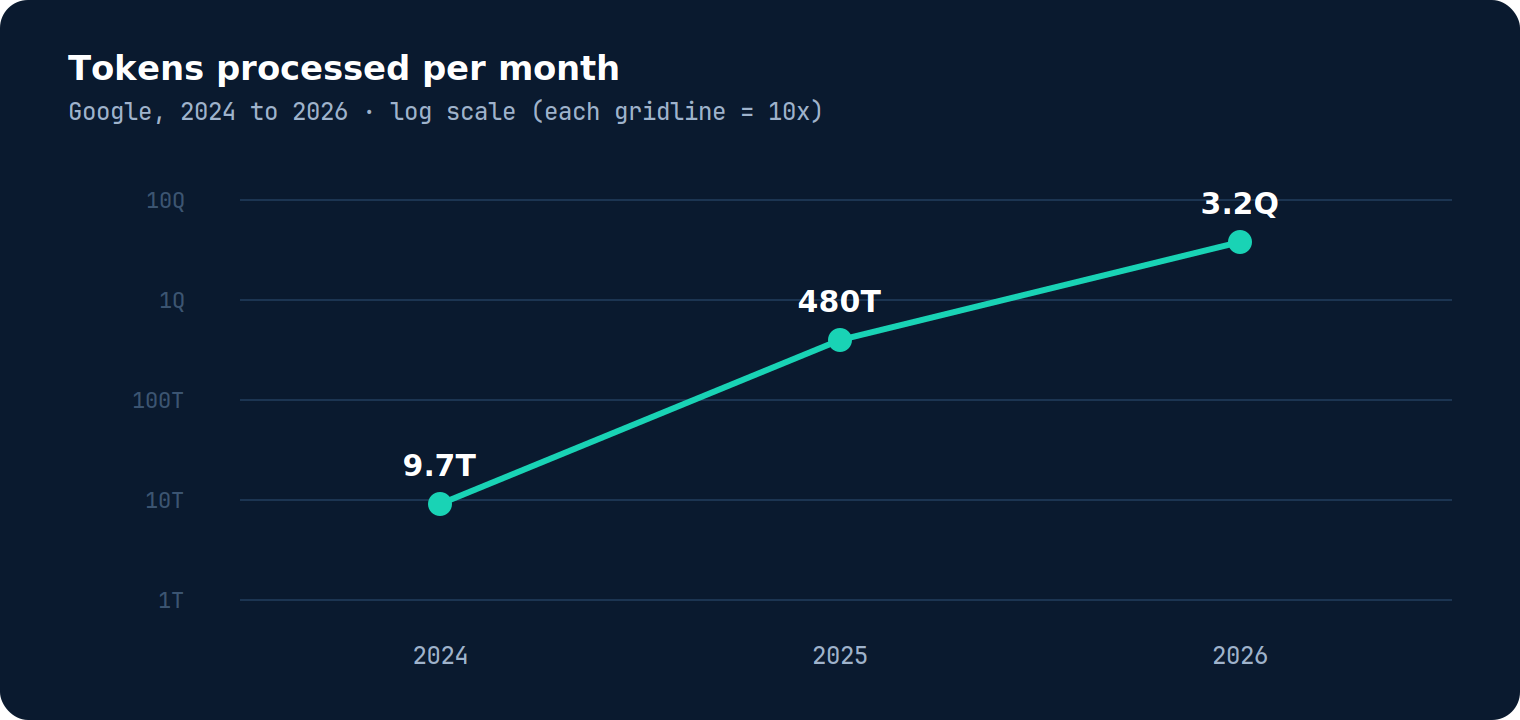
Google says it now processes 3.2 quadrillion tokens a month. Two years ago the figure was 9.7 trillion. That is not steady growth, it is a different category of number. You would expect cost to fall with it, since the price per token keeps dropping. It does not. Budgets tighten and limits get hit faster. So what changed?
The agent era changed what a token is for
A chatbot spends tokens to answer a question. An agent spends them to plan, search, load tool schemas, call tools, read results, retry, and hand off, then does it all again. The unit of work moved from one answer to one workflow, and a workflow is hungry in a way a single reply never was. On OpenRouter's data, a chatbot summarizing Hamlet runs about 30,000 tokens; an agent on a modest coding task can burn up to 20 million.
Cheap tokens were never the safety net
Over two years, price per token fell about 1,000x while volume rose about 10,000x. The efficiency gains were real, and they were swamped. Economists call this the Jevons paradox: when a resource gets cheaper to use, people use far more of it, so total spend rises rather than falls. Goldman Sachs expects another 24x ahead by 2030. Falling prices did not protect anyone. They hid the problem until volume caught up.
Prices fell ~1,000x. Volumes rose ~10,000x.
The efficiency story and the cost story are not the same story.
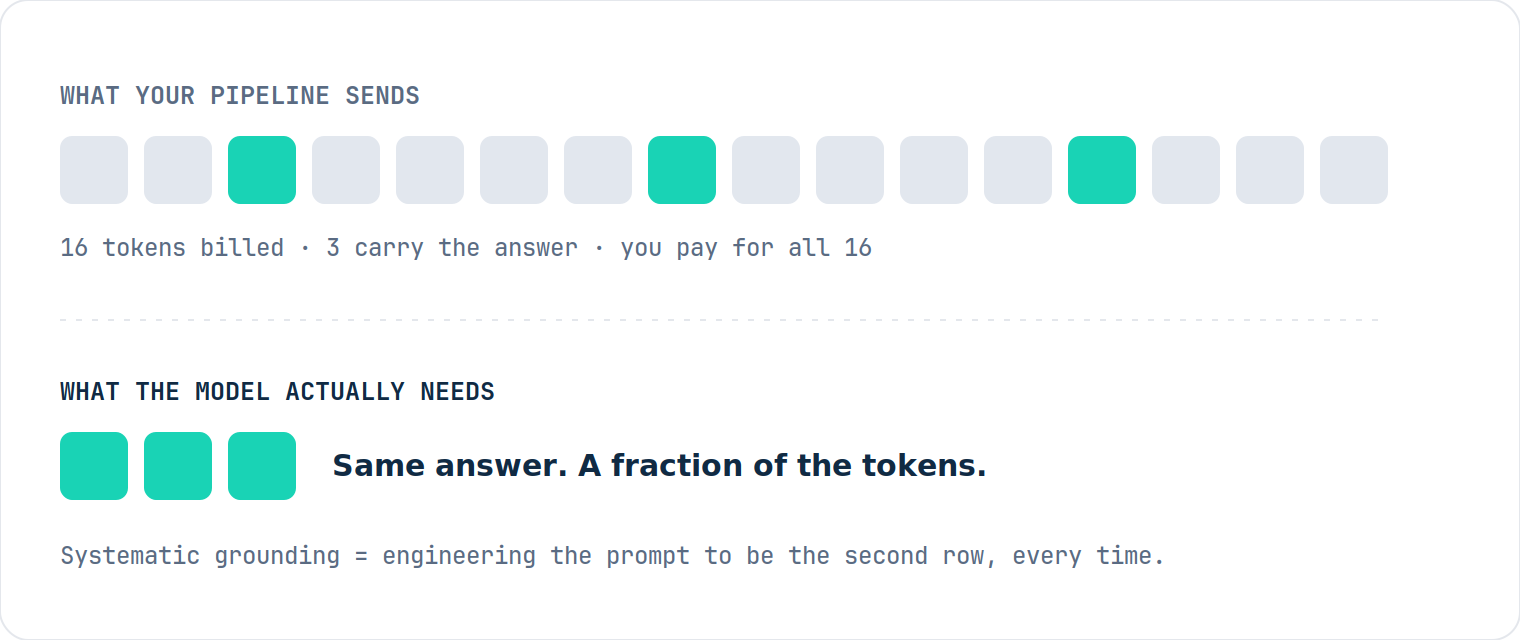
The token explosion is really a noise problem
Most of the explosion is not extra intelligence. It is noise: tokens spent carrying context the model never needed. Look at where they go:
- Most RAG pipelines over-fetch by 3x to 5x, padding every prompt with chunks that do not move the answer.
- Tool definitions are billed as input tokens on every call, often ~55,000 tokens before any work begins.
- Weak retrieval sends agents back to search again and again, the loops that triple a bill in months.
Research on agentic coding is blunt: these tasks use roughly 1,000x more tokens than chat, input dominates the bill, and more tokens do not reliably produce a better answer. Feeding an agent more does not make it smarter. The lever was never cheaper tokens. It is sending less noise.
What LightOn optimizes: signal density, not token price
Most relief works downstream: cheaper engines like vLLM, prompt caching to reuse what gets sent. Useful, but they still ship the noise at a lower rate. LightOn's bet is upstream, send fewer, higher-signal tokens in the first place. Late-interaction retrieval does exactly that, and the proof is a cost claim.
BrowseComp-Plus is the hardest public agentic-search benchmark: a fixed 100,000-document corpus and 830 hard queries. In production, search calls times tokens per call times queries is your bill, so search-call count is dollars per query. The top-ranked system needs around 209 LLM round-trips to win. LightOn's Reason-ModernColBERT, at 149 million parameters, reaches 87.59% in about 13. Roughly 16x less inference, for about 8 accuracy points.

The same idea drives ColGrep, which swaps blind pattern matching for local semantic code search. Inside Claude Code it wins 70% of head-to-heads against grep, cuts search operations by 56%, and saves about 60,000 tokens per question. Trivial on one query, but at scale it pays a team.
Projected at $9 / M tokens.
Systematic grounding: what it means for your stack
An agent in production is constantly immersed in your knowledge: every plan, tool call, and retry pulls context from somewhere. Systematic grounding means engineering that immersion to be high-signal at every step, by design rather than by luck. Most stacks ground their agent in noise instead: naive search, over-fetched chunks, bloated tool catalogs. Every breakage gets patched in tokens, every model upgrade re-breaks the pipeline. That is a leak with a monthly invoice. Grounding it systematically flips the defaults:
- Calibrated retrieval with high first-pass recall, so the agent does not loop.
- Fewer search calls, because each returns signal instead of a haystack.
- The right model for each task: a specialist like LightOnOCR-2 for parsing and search, the frontier model only for reasoning.
The result is an agent that thinks more while consuming less.
From research to a single endpoint
Everything above is open and yours to run: Reason-ModernColBERT, LateOn, LightOnOCR-2, powered by ColGrep, FastPlaid or NextPlaid. Download them, wire them together, tune them. For some teams that is the right path. The catch is it puts you back in the business of building and maintaining a retrieval pipeline, the exact tax this post is about. Someone owns the parser, the index, the reranker, and the rebuild every time a model moves. LightOn Console is the same research with the pipeline already built: those models assembled, served, and maintained behind one API.
The commercial answer: pay for actions, not tokens
This is why console.lighton.ai is priced the way it is. Three endpoints, /parse, /extract, and /search, billed per action rather than per token. A search is a search whether the model burns 5K tokens or 50K underneath. LightOn carries the token-volume risk; your bill scales with actions you control.
Ground your stack systematically
Stop paying full price for tokens your model never reads. Start with parse, extract, and search on a free tier.



.avif)
.avif)
