
.svg)

TL;DR
Meet LightOn Facets, the simplest way to find documents by what they are, not just what they say. Tag every file by type, status, or jurisdiction, and let faceted search pull the exact set you need. It plugs into hybrid search inside LightOn Console: lexical and semantic run together, chosen for you, and faceted search scopes the corpus before the query even runs.
Retrieval is a signal-to-noise problem. Every query tries to pull a handful of right documents out of everything else. Whatever noise survives lands in the model's context, or on the user's screen.
"Give me all NDAs, signed, valid in France, where the counterparty is Acme."
Run that against a full-text index and you get noise. "Acme" surfaces in unrelated files. "France" matches anything that mentions the country. "Signed" finds the verb, not the state of the contract. Keyword search reads words. It does not read what a document is.
Semantic search helps. Vectors catch the meaning that keywords miss. LightOn already runs both as hybrid search, so you never choose lexical or semantic, the system uses both plus other signals for you. But hybrid search still runs against everything. The noise is in the corpus before the query starts.
Faceted search fixes that. It narrows to the documents that fit before the search runs. You search the signed French NDAs, not the entire archive.
See faceted search narrow a real corpus. Try it in LightOn Console →
Scope before you search
A query carries structure, and so does a document. "All signed NDAs in France with Acme" is a four-field specification. Type is nda. Signed is true. Jurisdiction is FR. Counterparty is Acme.
Use those fields as a pre-filter and the search runs on a smaller, cleaner set. Ask the question across 10,000 documents and you get results drawn from 10,000 documents. Filter to the 885 that are type NDA, signed, and French-law first, then ask, and the search has far less room to bring back noise. It was scoped from the start.
This is faceted search, a feature every mature enterprise search system has, and one that few have brought to AI retrieval. Search engineer Doug Turnbull has made the case for it next to keyword and vector. LightOn ships it as Facets.
What LightOn Facets are
Facets bring faceted search to your documents. You classify files by type, set attribute values, then filter on those fields to scope what the search sees. They run on three layers: a schema you define once, a classification per file, and the values that fill it in.
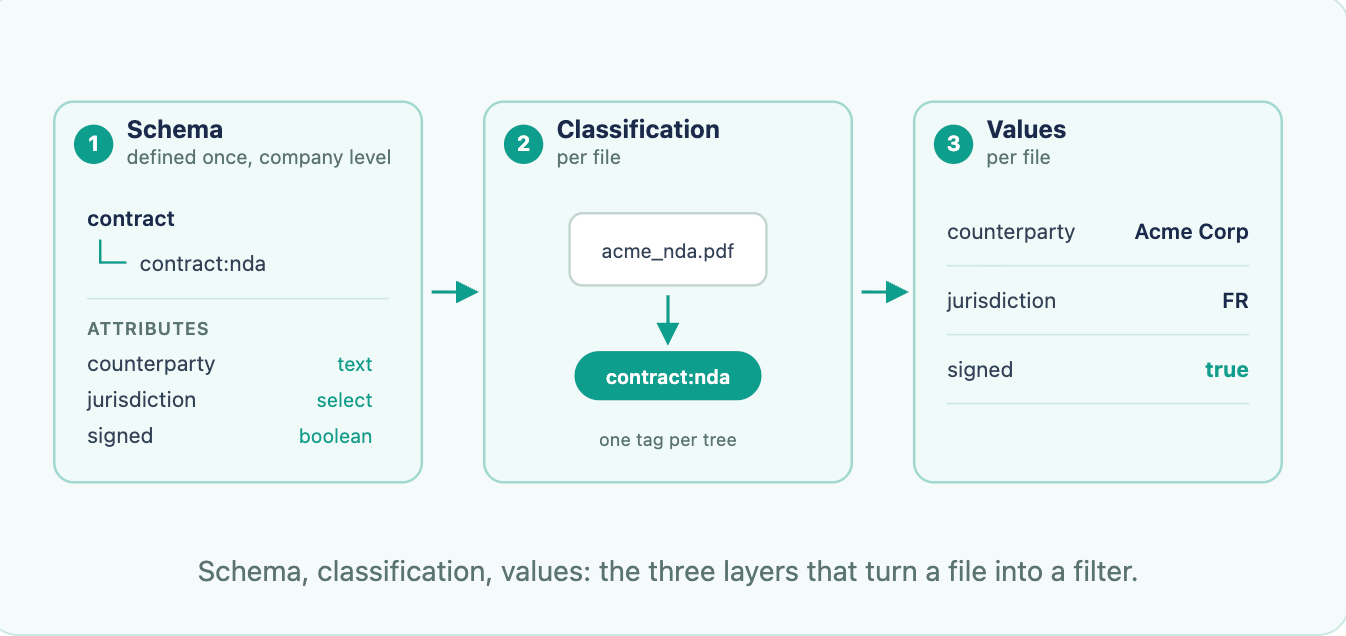
You design the schema once. A file can carry classifications from several trees at once: a contract in your legal tree, a retention record in another. You can apply classifications and values as files flow in, through the API or automatically with AI.
Two jobs faceted search does well
Pre-filter a search.
Scope a question to the documents that match before the query runs, and the answer comes back cleaner. The same logic handles requests semantic search cannot. "What was the building-height rule in Lyon in 2016" needs a hard filter on validity dates, not a guess at meaning. Faceted search is built for exactly that.
Return a list of documents, not an answer.
Some requests are not RAG at all. "Give me every signed NDA, French law, counterparty Acme" asks for a list, not a written reply. Faceted search returns the exact set on its own, with no generation step. When you do want an answer, you can still scope it: ask the question only across the documents that match.
How it works
Three calls take you from raw files to scoped retrieval.
Start by creating your classification trees, once. POST /api/v3/content-types defines content types and attributes. Skip the blank page: pick a starter kit for legal, finance, healthcare, tech, or manufacturing, or build your own up to four levels deep, with seven attribute types from boolean to multi-select.
Next, enrich your files and populate your facets. POST /api/v3/files/{id}/facets assigns a content type and fills in its attribute values, from existing metadata you import or automatically using enrichment mechanisms where AI extracts them from the documents.
Then search, scoped. POST /api/v3/search takes your facets as typed filters, for example content_type ["legal:contract"] and attribute ["signature_date:2024"], and runs the query only over that set.
That last call is where the noise disappears. A few filters turn vague, expensive queries into exact ones:
Faceted search your agents can discover on their own
In a business app, you know your catalog. You define the Facets and apply the filters yourself, the way a date filter narrows results behind a button.
An agent does not. It starts with a raw query and nothing else. It cannot browse a catalog of 5,000 facets to find the ones that fit. So the flow flips.
The agent makes two calls. First it discovers: it sends the query to GET /api/v3/content-types with include_attributes=true, and gets back the content types and attributes that look relevant. "What are the contracts signed in 2024" returns legal:contract, with typed attributes like signature_date (date), counterparty (text), and contract_value (number). Then it runs a scoped search: POST /api/v3/search with those facets as typed filters, scoped to 2024 contracts. The agent decides which facets to apply, or runs without them.
This is faceted search in the agentic era. The filters are no longer clicked by a human down the side of a page. They are surfaced from a plain query, and the agent reasons about which ones to apply. Mature search systems have had facets for years. LightOn built its search recently, and agent-first, so faceted search is exposed for agents from the start.
Lexical, semantic, and faceted search, behind one API, over one index, on European infrastructure.
Try it in LightOn Console
Spin up faceted search in LightOn Console. Build a classification tree, classify your first files, and filter by type and attribute in minutes.
Ready to go deeper? The Facets tutorial walks through the schema, the classification calls, and the filter syntax end to end.



.avif)
.avif)
