
.svg)
TL;DR
An independent benchmark from Offenburg University and the University of Mannheim tested 21 PDF parsers on 451 tables. LightOnOCR-2 scored 9.08/10, ranking #1 among all dedicated OCR models, ahead of Mathpix, Qwen3-VL-235B, GPT-5 mini, and Claude Sonnet 4.6. It runs on a single GPU, weighs just 1B parameters, and ships under Apache 2.0.
Get the Table Wrong, Get Everything Wrong
The most valuable information in enterprise documents doesn't live in paragraphs. It lives in tables.
Financial statements. Clinical trial results. Defence procurement specs. Engineering reports. Compliance matrices. Pricing schedules. The numbers that drive decisions sit inside rows and columns, and getting them wrong has consequences.
Get the table wrong and your RAG pipeline hallucinates numbers. Your agent makes decisions on corrupted data. Your analyst misses the cell that changes the deal.
Table extraction is also the critical first step in any serious Search and Reason workflow over enterprise documents. Everything downstream, retrieval, reasoning, generation, depends on getting this right.
And yet, most parsers still struggle with it.
The Benchmark
Researchers from the Institute for Machine Learning and Analytics (IMLA) at Offenburg University and the University of Mannheim just published an independent evaluation of 21 PDF parsers on table extraction.
The study “ Benchmarking PDF Parsers on Table Extraction with LLM-based Semantic Evaluation “ tested each parser across 451 tables from 100 synthetic pages, scoring outputs on a 0–10 scale using an LLM-as-a-judge approach validated against over 1,500 human ratings. Tables were broken down by structural complexity: simple, moderate, and complex.
📄 Read the full paper: arxiv.org/abs/2603.18652
The Results
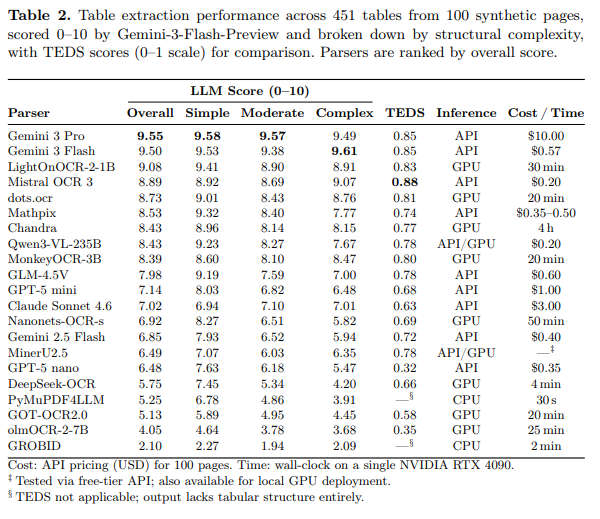
LightOnOCR-2 scored 9.08/10 overall, placing it:
- #1 among all dedicated OCR models
- #3 overall, behind only Gemini 3 Pro (9.55) and Gemini 3 Flash (9.50) — both closed-source API-only models priced at $10.00 and $0.57 per 100 pages respectively
Here's how it stacks up against the field:
And the score distributions tell an even clearer story:
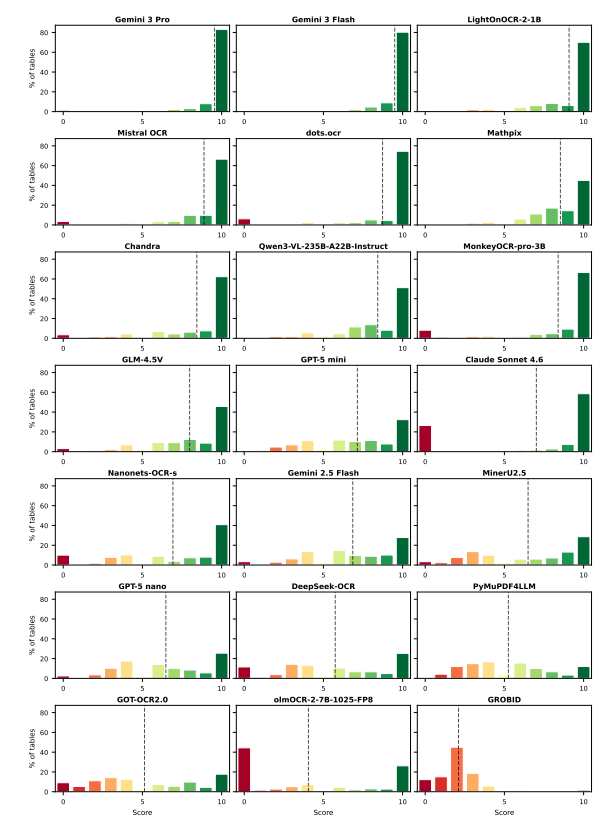
LightOnOCR-2's distribution is tightly concentrated in the 8-10 range, consistent, reliable extraction across simple and complex table structures alike.
What Makes This Different
Let's be direct about what this means.
The model that outperformed OpenAI's GPT-5 mini, Anthropic's Claude Sonnet 4.6, Alibaba's Qwen3-VL-235B, and Mathpix is:
- 1B parameters : small enough to run on a single NVIDIA RTX 4090
- Apache 2.0 licensed : fully open source, no strings attached
- Deployable on-premise : behind your firewall, on your infrastructure, with your data never leaving your environment
No API dependency. No per-page pricing that scales into the thousands. No sending sensitive financial, legal, or medical documents to a third-party endpoint.
This is what we build at LightOn. Models that belong to the enterprises that use them.
Under the Hood
LightOnOCR-2-1B is our second-generation end-to-end vision-language OCR model. No multi-stage pipelines. No stitched-together components. A single 1B-parameter model that converts document pages into clean, naturally ordered text — and optionally outputs bounding boxes for embedded figures and images when your workflow needs layout cues.
It ships under Apache 2.0, with a full family of open-weight checkpoints: OCR-focused variants, bbox-capable variants, and base checkpoints ready for fine-tuning, domain adaptation, and layout-oriented applications.
Performance: LightOnOCR-2-1B substantially improves over our first generation and is now state-of-the-art on OlmOCR bench — outperforming Chandra-9B by more than 1.5 percentage points overall, while being nearly 9× smaller.
Speed: 3.3× faster than Chandra OCR, 1.7× faster than OlmOCR, 5× faster than dots.ocr, 2× faster than PaddleOCR-VL-0.9B, 1.73× faster than DeepSeekOCR.
Training data: We're releasing two open annotation datasets used during training: lightonai/LightOnOCR-mix-0126 (23M+ high-quality annotated document pages) and lightonai/LightOnOCR-bbox-mix-0126 (~500K annotations including bounding boxes for figures and images).
Full technical details in the preprint.
Get Started
Download the model: 🤗 huggingface.co/lightonai/LightOnOCR-2-1B
Deploy at scale with LightOn: 🚀 lighton.ai/api
Whether you're building document intelligence pipelines, powering RAG over financial data, or processing thousands of pages a day, LightOnOCR-2 gives you state-of-the-art table extraction that you own, you control, and you deploy wherever you need it.
Ready to put LightOnOCR-2 to work on your documents? Talk to our team and see what enterprise-grade OCR looks like.



.avif)
.avif)
