
.svg)

TL;DR
- Agent-ModernColBERT adapts late-interaction retrieval to agentic search, where queries include reasoning traces produced by the agent.
- On the BrowseComp-Plus benchmark, it improves over Reason-ModernColBERT by roughly 10% while keeping the same 150M-parameter footprint.
- With GPT-OSS-120B and a simple get_document function, the fully open setup reaches 72.53 accuracy, above the original GPT-5 + Qwen3-Embed-8B benchmark configuration, although that baseline did not expose get_document.
- Agent-ModernColBERT is competitive with AgentIR-4B while being 26× smaller and trained on the same data.
- Training takes about five minutes. The model, training code, and dataset are open.
Agentic retrieval is changing the shape of the query. In addition to the query, the agent is creating reasoning traces about what it is searching and why. Usual retrieval setup discard those clues, while AgentIR append them to the query. By applying AgentIR to late interaction models, we get a 10% increase over the already state-of-the-art Reason-ModernColBERT. Combined to GTP-OSS-120B, we can now reach the original performance of GPT-5 combined to Qwen3-Embed-8B, with a model 54× smaller and a fully open source agent.
.png)
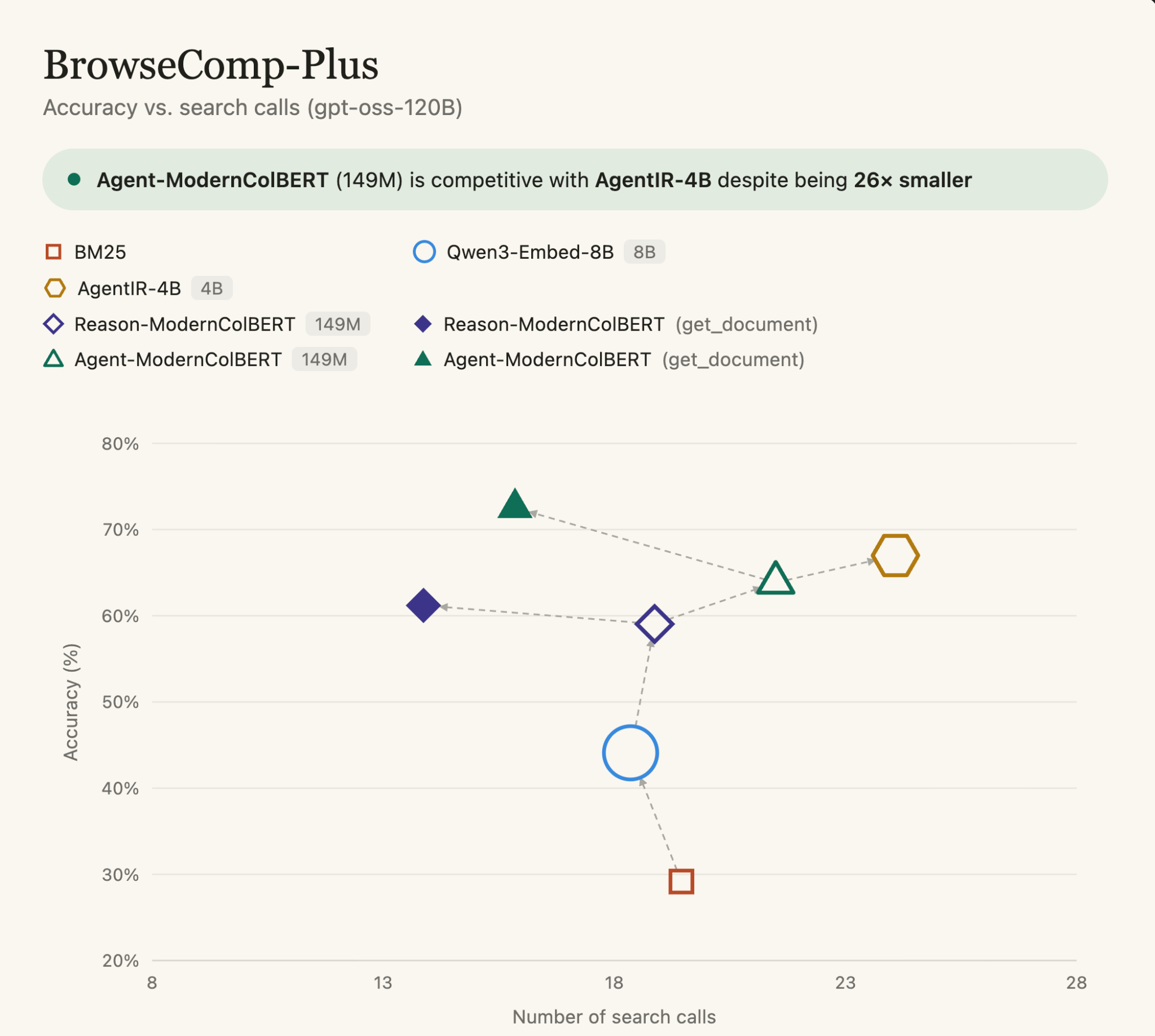
Most notably, Agent-ModernColBERT is competitive with AgentIR-4B, a dense model 26× larger trained on the same data, highlighting once again the edge of late interaction in agentic search.
The pattern keeps holding
Two months ago, Reason-ModernColBERT reached 87.59% accuracy on BrowseComp-Plus with GPT-5, a 7.59-point jump over the previous best while leading on recall and calibration error. A 149M late-interaction retriever was outperforming dense models up to 54× larger. Full write-up: The Bloated Retriever Era Is Over.
BrowseComp-Plus is designed to test retrieval inside Deep Research-style workflows: hard questions, a fixed corpus, and a setup where the retriever has to surface evidence useful enough for an agent to answer. It does not only ask whether the retriever can rank documents well. It asks whether better retrieval actually helps the agent solve the task.
Reason-ModernColBERT was not trained for agentic search specifically. It was trained for reasoning-intensive retrieval in general. The obvious next question was simple:
What happens if you train a late-interaction model directly for retrieval inside reasoning loops?
AgentIR and DR-Synth
Zijian Chen, who created BrowseComp-Plus, also released AgentIR.
The core idea is straightforward: in agentic search, the query is rarely just a query. Before searching, the agent has usually decomposed the task, formed hypotheses, ruled out dead ends, and decided what evidence it needs next.
Most retrieval pipelines throw that context away. They search only on the rewritten query.
AgentIR does something different: it concatenates the agent’s reasoning trace directly into the retrieval query.
To support this setup, the team released DR-Synth, a dataset of synthetic agent trajectories, and trained AgentIR-4B, a dense 4B retriever. AgentIR-4B outperformed the larger ReasonIR-8B and pipelines using rerankers.
This matters because Reason-ModernColBERT was itself built from the ReasonIR line of work. The recipe was already familiar: when a strong dense retriever and its training data are released, train a late-interaction model on the same signal with PyLate, then test whether multi-vector retrieval can do more with less.
Agent-ModernColBERT
Agent-ModernColBERT built on this now familiar recipe by fine tuning a late interaction model on the DR-Synth data.
It is a 149M-parameter late-interaction retriever trained to handle retrieval queries that include agent reasoning traces. Training takes about five minutes.
The result is a small retriever that is directly adapted to the AgentIR setting, while preserving the core advantage of late interaction: token-level matching instead of compressing the entire query and document into a single vector.The open-source result is the important one: with GPT-OSS-120B and a simple get_document function, Agent-ModernColBERT reaches 72.53 accuracy. That is above the original GPT-5 + Qwen3-Embed-8B configuration from BrowseComp-Plus, although the two scaffolds are not identical because the original baseline did not expose get_document.
That caveat matters. So does the result.
A 149M retriever, paired with an open LLM and a lightweight document-reading tool, crosses the original closed-model benchmark configuration. Fully open. Smaller. Cheaper. More accurate in this setup.
The AgentIR-4B comparison is the other key result. Agent-ModernColBERT is trained on the same data and uses the same prompt as AgentIR, down to the same incorrectly escaped line break, for comparability, yet remains competitive while being 26× smaller.
At that point, the dense-scaling argument starts to run out of room.
Why reasoning traces favor late interaction
Agentic retrieval changes the shape of the query.
A standard search query is often short: a few keywords, an entity, a question. An agentic query can be much richer. It may contain the current hypothesis, intermediate reasoning, constraints, and a description of the missing evidence.
That is a lot of information to compress into one vector.
Late interaction models do not need to make that compression as aggressively. They keep token-level representations and compare query tokens against document tokens at retrieval time. When the query contains a reasoning trace, this becomes especially useful: the retriever can match different parts of the trace to different pieces of evidence in the document.
That is why Reason-ModernColBERT was already strong on BrowseComp-Plus without being trained for agentic search. Agent-ModernColBERT shows what happens when the training data is aligned with the agentic setting directly.
Why this changes the cost equation
Every retrieval call inside a Deep Research loop costs tokens, latency, and money.
A better retriever reduces the number of search iterations needed to reach an answer. A smaller retriever reduces the cost of each one. Late interaction helps on both sides.
For teams building Deep Research-style agents over enterprise knowledge bases, this is not just a benchmark detail. Retrieval runs inside the loop. It has to be fast, cheap, and accurate enough for the agent to decide what to read next.
An 8B dense embedder is expensive to serve at scale and difficult to keep responsive inside long reasoning loops. Agent-ModernColBERT changes the equation on both sides: smaller retrieval steps, and fewer of them.
In the GPT-OSS-120B setup, Agent-ModernColBERT reaches higher accuracy than AgentIR-4B while using fewer search calls. That matters because every search inside a Deep Research loop adds latency, token usage, and cost. A 149M late-interaction retriever does not just make retrieval cheaper to serve. It also helps the agent get to the right evidence faster.
As retrieval becomes more agentic, the bottleneck does not look like model scale.
It looks like dense compression itself.
Open and reproducible
Models
- Agent-ModernColBERT: agentic retrieval, 149M parameters
- Reason-ModernColBERT: reasoning-intensive retrieval, 149M parameters
- LateOn-Code: code retrieval, 17M / 149M parameters
Tools & infrastructure
- PyLate: train late-interaction models in a few lines of code
- The exact training script used for Agent-ModernColBERT is available [here]
- ColGrep: semantic code search for terminals and coding agents
- NextPlaid: local-first multi-vector database
Datasets & benchmarks
Pull the weights from Hugging Face. Run late-interaction retrieval against your own corpus through /search in LightOn Console. Building Deep Research-style agents over enterprise knowledge bases? Talk to us.
Agent-ModernColBERT was developed by Antoine Chaffin, Research Engineer at LightOn.
.png)


.avif)
.avif)
