.svg)

TL;DR
Un benchmark indépendant mené par l'Université d'Offenburg et l'Université de Mannheim a évalué 21 parseurs PDF sur 451 tableaux. LightOnOCR-2 obtient un score de 9.08/10, se classant #1 parmi tous les modèles OCR dédiés, devant Mathpix, Qwen3-VL-235B, GPT-5 mini et Claude Sonnet 4.6. Il tourne sur un seul GPU, ne pèse que 1B paramètres et est distribué sous licence Apache 2.0.
Un tableau mal lu, tout est faussé.
L'information la plus précieuse des documents d'entreprise ne se trouve pas dans les paragraphes. Elle se trouve dans les tableaux.
États financiers. Résultats d'essais cliniques. Cahiers des charges de marchés publics de défense. Rapports d'ingénierie. Matrices de conformité. Grilles tarifaires. Les chiffres qui orientent les décisions sont enfermés dans des lignes et des colonnes, et les extraire de travers a des conséquences.
Un tableau mal extrait et votre pipeline RAG hallucine des chiffres. Votre agent prend des décisions sur des données corrompues. Votre analyste passe à côté de la cellule qui change la donne.
L'extraction de tableaux est aussi la première étape critique de tout workflow sérieux de Search and Reason sur des documents d'entreprise. Tout ce qui suit, récupération, raisonnement, génération, dépend de la qualité de cette étape.
Et pourtant, la plupart des parseurs échouent encore sur ce point.
Le Benchmark
Des chercheurs de l'Institute for Machine Learning and Analytics (IMLA) de l'Université d'Offenburg et de l'Université de Mannheim viennent de publier une évaluation indépendante de 21 parseurs PDF sur l'extraction de tableaux.
L'étude, Benchmarking PDF Parsers on Table Extraction with LLM-based Semantic Evaluation, a testé chaque parseur sur 451 tableaux issus de 100 pages synthétiques, en attribuant des scores de 0 à 10 via une approche LLM-as-a-judge validée par plus de 1 500 évaluations humaines. Les tableaux étaient répartis par complexité structurelle : simple, modérée et complexe.
📄 Lire l'article complet : arxiv.org/abs/2603.18652
Les résultats
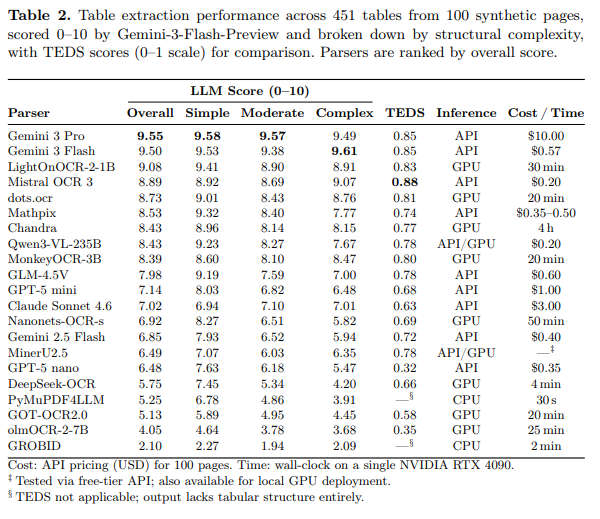
LightOnOCR-2 obtient un score global de 9.08/10, ce qui le place :
- #1 parmi tous les modèles OCR dédiés
- #3 au classement général, derrière Gemini 3 Pro (9.55) et Gemini 3 Flash (9.50), deux modèles propriétaires accessibles uniquement via API, facturés respectivement 10,00 $ et 0,57 $ pour 100 pages
Voici comment il se positionne face au reste du marché :
Et la distribution des scores est encore plus parlante :
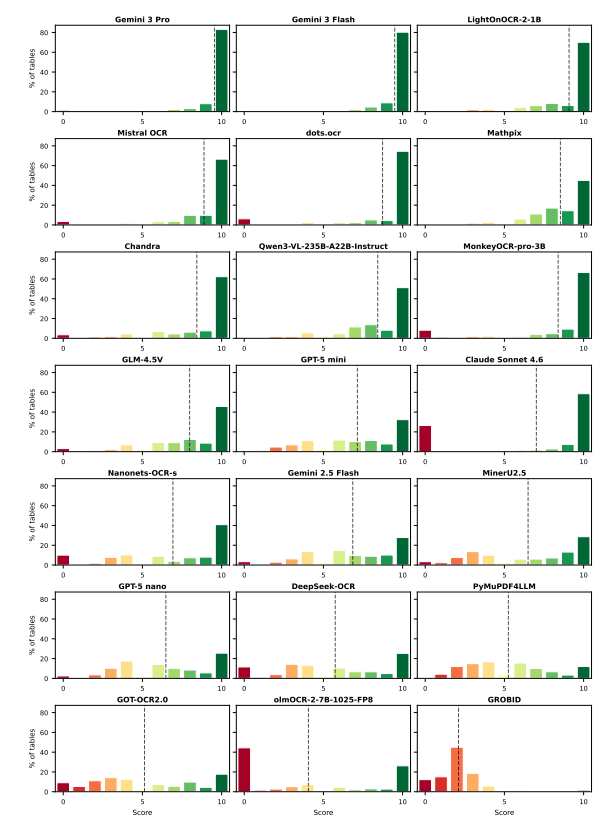
La distribution de LightOnOCR-2 est fortement concentrée dans la plage 8–10 : une extraction fiable et régulière, aussi bien sur des tableaux simples que complexes.
Ce qui change la donne
Soyons directs sur ce que cela signifie.
Le modèle qui a surpassé GPT-5 mini d'OpenAI, Claude Sonnet 4.6 d'Anthropic, Qwen3-VL-235B d'Alibaba et Mathpix, c'est :
- 1B paramètres : suffisamment compact pour tourner sur un seul NVIDIA RTX 4090
- Licence Apache 2.0 : entièrement open source, sans aucune restriction
- Déployable on-premise : derrière votre pare-feu, sur votre infrastructure, sans que vos données ne quittent jamais votre environnement
Aucune dépendance à une API. Aucune facturation à la page qui explose à grande échelle. Aucun envoi de documents financiers, juridiques ou médicaux sensibles vers un service tiers.
C'est ce que nous construisons chez LightOn. Des modèles qui appartiennent aux entreprises qui les utilisent.
Sous le capot
LightOnOCR-2-1B est notre modèle OCR vision-langage de seconde génération, entraîné de bout en bout. Pas de pipeline multi-étapes. Pas de composants assemblés. Un seul modèle d'1 milliard de paramètres qui convertit des pages de documents en texte propre et naturellement ordonné avec en option la détection de boîtes englobantes pour les figures et images embarquées, pour les workflows qui ont besoin de repères de mise en page.
Il est distribué sous licence Apache 2.0, avec une famille complète de checkpoints open-weight : variantes orientées OCR, variantes avec boîtes englobantes, et checkpoints de base prêts pour le fine-tuning, l'adaptation domaine et les applications orientées mise en page.
Performance: LightOnOCR-2-1B améliore substantiellement notre première génération et atteint l'état de l'art sur OlmOCR bench, surpassant Chandra-9B de plus de 1,5 point de pourcentage, tout en étant près de 9 fois plus petit.
Vitesse: 3,3× plus rapide que Chandra OCR, 1,7× plus rapide qu'OlmOCR, 5× plus rapide que dots.ocr, 2× plus rapide que PaddleOCR-VL-0.9B, 1,73× plus rapide que DeepSeekOCR.
Données d'entraînement: Nous publions deux jeux de données d'annotation ouverts utilisés pendant l'entraînement : lightonai/LightOnOCR-mix-0126 (plus de 23M de pages de documents annotées) et lightonai/LightOnOCR-bbox-mix-0126 (~500K annotations incluant des boîtes englobantes pour figures et images).
Tous les détails techniques dans le preprint.
Pour commencer
Télécharger le modèle : 🤗 huggingface.co/lightonai/LightOnOCR-2-1B
Déployer à grande échelle avec LightOn : 🚀 lighton.ai/api
Que vous construisiez des pipelines d'intelligence documentaire, alimentiez du RAG sur des données financières ou traitiez des milliers de pages par jour, LightOnOCR-2 vous offre une extraction de tableaux état de l'art que vous possédez, que vous contrôlez et que vous déployez où vous le souhaitez.
Prêt à mettre LightOnOCR-2 au service de vos documents ? Contactez notre équipe et découvrez ce que l'OCR on-premise de niveau entreprise peut faire pour vous.



.avif)
.avif)