
.svg)

TL;DR
Document-heavy vertical AI is one of the highest-value categories in enterprise software right now. Legal-tech, procurement, finance, construction, every sector with large unstructured document volumes is being rebuilt. The teams winning in these verticals are not winning on retrieval quality. They are winning on domain expertise, distribution, and speed of iteration. Retrieval is a prerequisite, not a differentiator. The question is how much of your roadmap you are willing to spend on infrastructure that is not your moat.
Every AI Product Hits This Wall
Your first enterprise client uploads scanned contracts from 2003, Word tables with merged cells, reports mixing two languages, handwritten annotations on typed documents. Your pipeline was built on clean digital PDFs. It returns garbage.
You now own four problems that were not on your roadmap six weeks ago.
The Production Gap - What Actually Breaks and Why
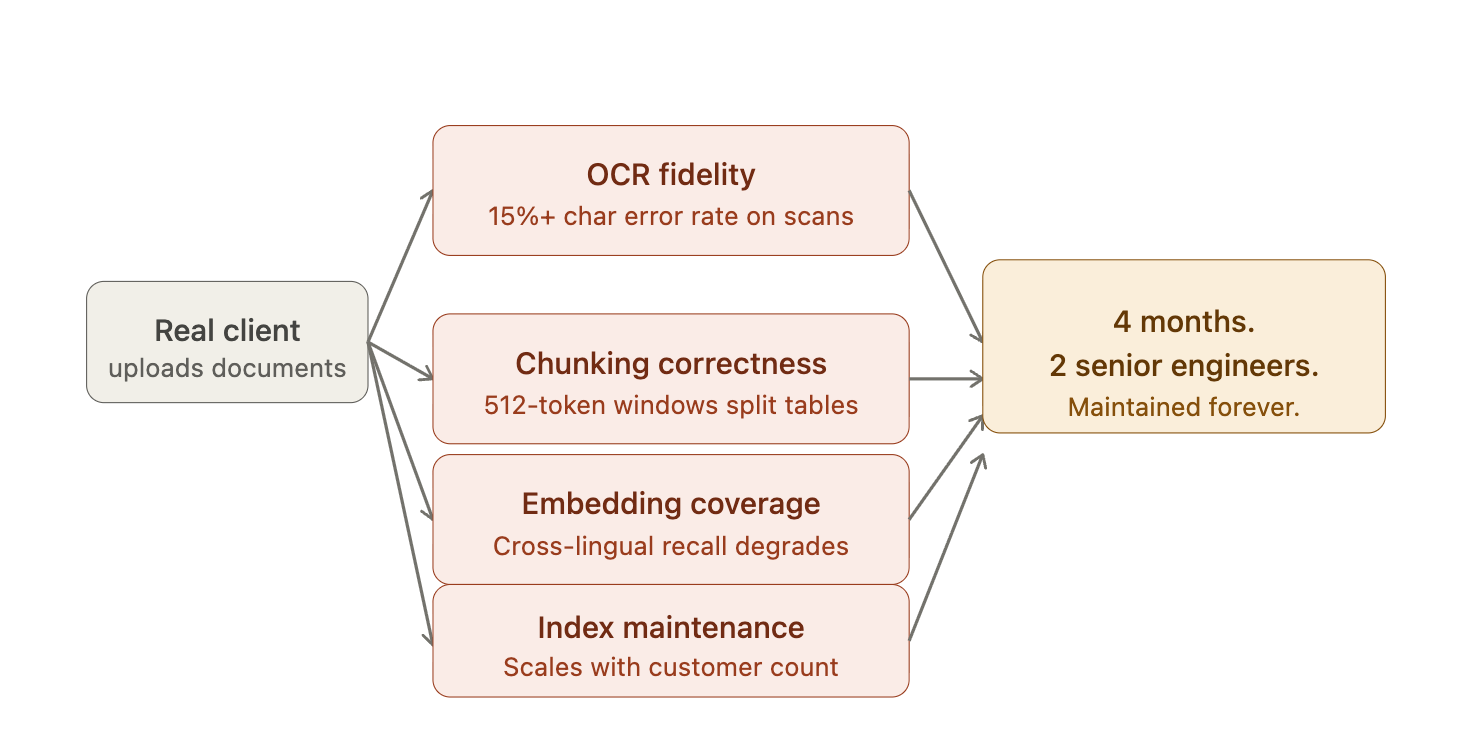
OCR fidelity.
Standard Tesseract-based wrappers fail on anything outside clean digital text. Character error rates above 15% on scanned documents compound directly into retrieval noise downstream. Every bad character is a bad token in a bad embedding.
Chunking correctness.
Fixed-size chunking destroys table structure. A 512-token window splits a financial table mid-row. Semantic chunking on multi-column layouts produces chunks that mix unrelated content from adjacent columns. Both patterns degrade recall in ways that are hard to debug because the failure is silent: the system returns results, just wrong ones.
Embedding coverage.
Most production embedding models were trained on English-dominant corpora. Cross-lingual retrieval performance drops sharply on underrepresented languages.
Index maintenance.
Every document update requires re-chunking, re-embedding, partial index rebuilds. Without a managed pipeline this becomes an ops burden that scales with your customer count, not your engineering capacity.
Four months. Two senior engineers. Your retrieval layer is now more complex than your actual product. It needs to be maintained forever.
The best teams skip all of this entirely.
What you are actually competing on
Ask what a competitor cannot copy:
Domain expertise - Distribution - Understanding of the buyer's workflow - Product intuition built from a hundred sales calls in your vertical.
Your chunking strategy is not on this list. Neither is your reranking logic, your embedding model selection, or your parsing pipeline. These are solved infrastructure problems. The moment someone productizes them well, they stop being differentiation. They already have been.
Three endpoints
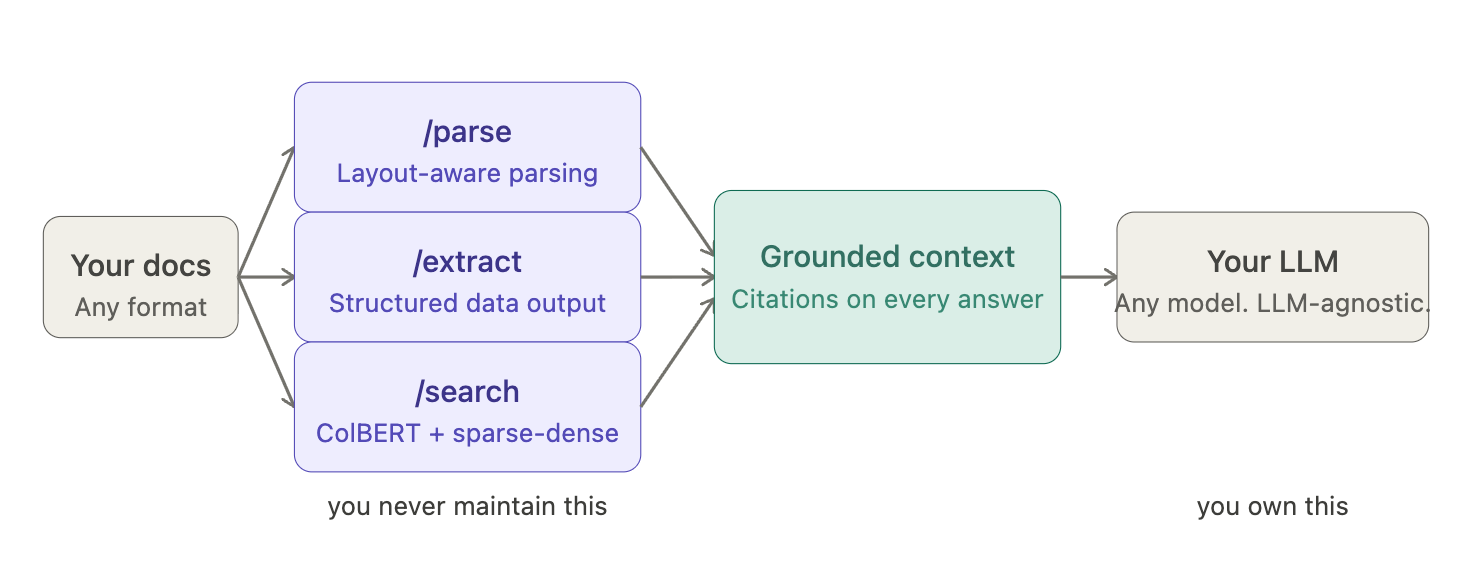
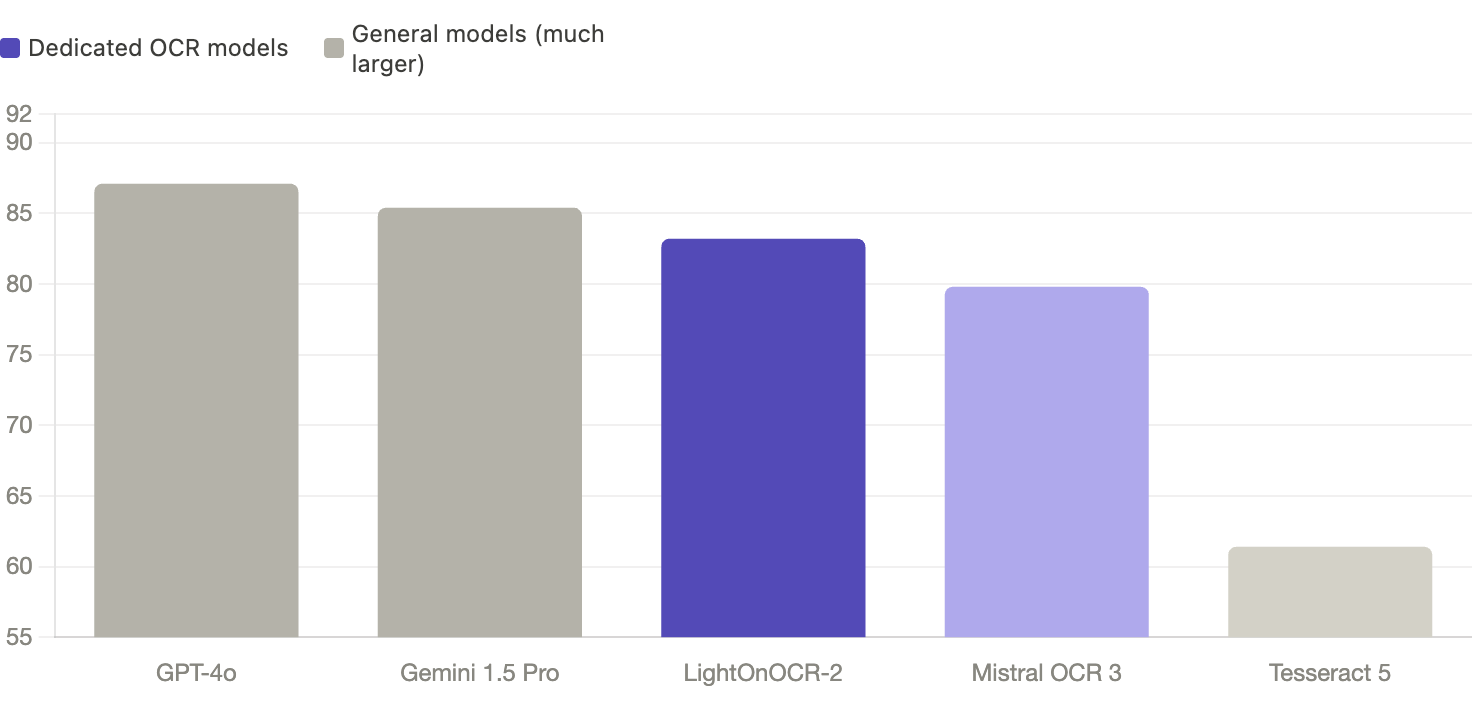
/parse runs LightOnOCR-2. 83.2 on OlmOCR-Bench, first among dedicated OCR models, third overall behind models nine times its size.
Layout-aware parsing handles multi-column documents, tables, handwriting, and 20-plus languages natively. The parser preserves the layout graph rather than stripping to raw text, which means downstream chunking operates on structure, not noise.
/extract returns structured data from documents that were never designed to be machine-readable. Merged cells, amounts buried in footnotes, clauses split across pages, extraction decisions are made with full layout context, not on a flattened text stream.
/search uses late-interaction retrieval built on ColBERT architecture combined with sparse-dense hybrid indexing. Token-level matching rather than single-vector approximation means precision holds on long documents and domain-specific terminology. Thirty papers. Eleven PhDs. 45 million model downloads on Hugging Face. Semantic, lexical, and visual signals combined. Source citations on every answer.
The API is priced per query, runs SaaS or on-premise depending on your data sovereignty requirements, and isolates workspaces for multi-tenant products. Integration takes days. Index maintenance takes zero engineers.
The org chart that ships
Two engineers who can call an API and read documentation. No retrieval team, no infrastructure backlog. The headcount that would have gone into parsing pipelines stays on the domain problem, the vertical knowledge, the workflow integrations, the product decisions that a competitor cannot reverse-engineer from your changelog.
That is the actual moat.
See what the pipeline looks like as an API: lighton.ai/api
.png)


.avif)
.avif)
