
.svg)

TL;DR
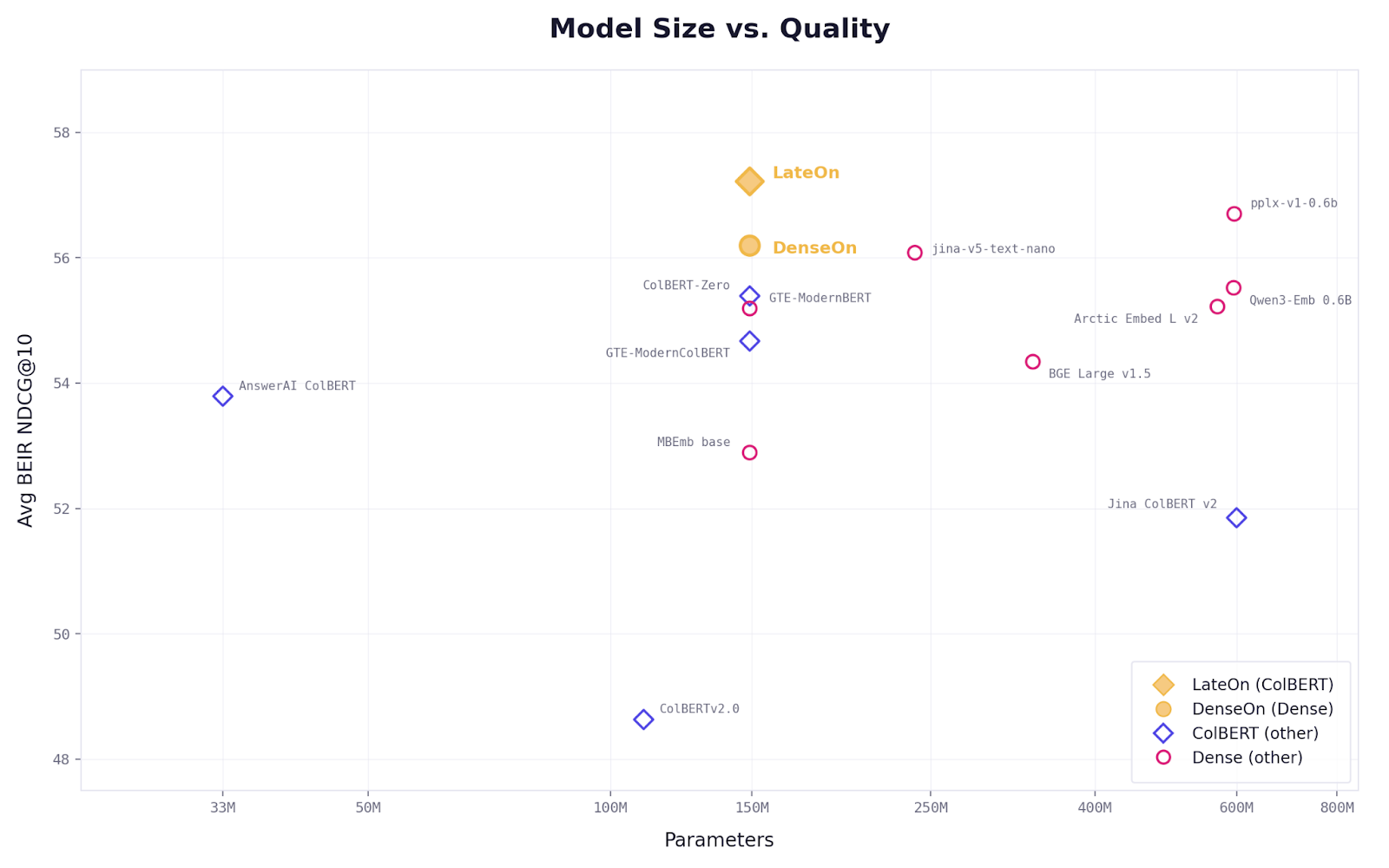
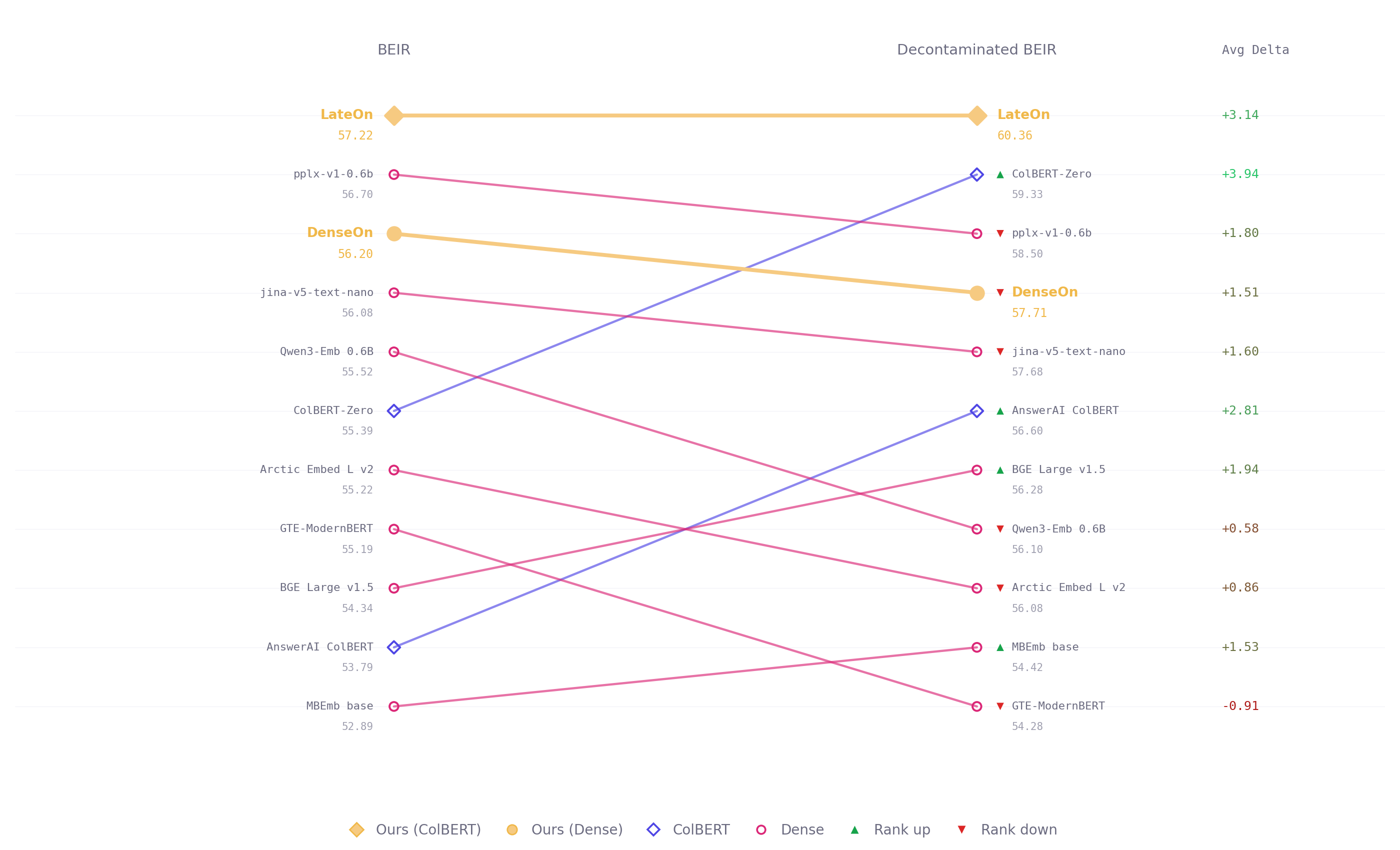
LightOn releases LateOn and DenseOn, two open retrieval models under Apache 2.0. LateOn is a multi-vector ColBERT model that scores 57.22 NDCG@10 on BEIR, the first ColBERT model to cross both the 56 and 57 marks. DenseOn is its dense counterpart, scoring 56.20 NDCG@10, ahead of the four times bigger Qwen3-Embedding-0.6B and the first base-size dense model to exceed 56 on the benchmark. Both run at 149M parameters. LightOn also evaluated both models on a decontaminated version of BEIR, stripping all documents found in training data from the evaluation corpora. The pattern is consistent: late interaction models generalize better on out-of-domain data. All four ColBERT models hold or improve their ranking while dense models dropped.
Benchmark scores are easy to inflate because training corpora and evaluation corpora overlap. A model tuned on that overlap looks better than it is, and once you deploy it on your own documents, the quality drops. We ran evaluation on a decontaminated version of BEIR, stripping every document found in our training data from each evaluation corpus. What remained measures generalization on unseen data, not familiarity with the test set.
LateOn and DenseOn were trained on identical data, at identical size, with different architectures. DenseOn is the best 150M dense model on BEIR. LateOn beats it. LateOn is also the retriever we run in production inside LightOn's search pipeline, and we are releasing it today under Apache 2.0. The decontaminated results explain why that distinction matters.
Dense Gets You to the Benchmark. Late Interaction Gets You to Production.
DenseOn reaches 56.20 NDCG@10 on BEIR, best base-size dense model on the benchmark, ahead of models four times larger. It was trained on the same data, with the same compute budget and the same objectives as LateOn. It is a strong model.
Then we ran the decontaminated evaluation. The premise is straightforward: when a model's training data contains documents that also appear in the evaluation corpus, the benchmark score measures familiarity as much as retrieval quality. Remove those documents, and what remains is the harder test, the one that matters for production, samples the model was not tuned on, queries it cannot pattern-match against memory.
Ranking of dense models dropped consistently. ColBERT models’ held. Average delta under decontamination was +2.01 NDCG for dense models and +3.55 for multi-vector. LateOn pulls further ahead. ColBERT-Zero climbs from 6th to 2nd.
The reason is architectural. Dense models compress a document into a single vector at index time, which is efficient but lossy. Late interaction models retain token-level representations and compute the match at query time, which preserves information that dense compression discards. On familiar data the difference is small. On out-of-domain data it compounds and if you are building a product on top of retrieval, your documents are almost certainly internal, niche, or domain-specific.
Why LateOn is the retriever you need for your data
LateOn scores 57.22 NDCG@10 on BEIR. First ColBERT model. Under decontamination, it reaches 60.36 and widens the gap.
The fact that matters more: it has been running in production inside LightOn's search pipeline before this release. We did not build a model for the benchmark and then ship it. We built the retriever our product needed, confirmed it was the best, and are releasing it today under Apache 2.0.
It sits inside the only hybrid search engine combining multi-vector late interaction, dense semantic search, and BM25 in a single endpoint. LightOnOCR-2 processes the documents, LateOn retrieves across them. Each layer in the pipeline handles a different retrieval failure mode. The full stack is available today via the LightOn API.
We also built the infrastructure to run late interaction at scale. PyLate for training and evaluating ColBERT models. FastPLAID for high-throughput inference. The ecosystem around multi-vector retrieval is sparse. We filled the gaps we needed and made everything open source.
Pull LateOn from HuggingFace. Run it on your data. Or get your API key and ship now!
Technical Deep Dive
The full technical write-up is on HuggingFace: training setup, architecture decisions, benchmark methodology, and what we learned along the way.
[Read it here]
.png)


.avif)
.avif)
