
.svg)

TL;DR
Spawn an agent into a folder of papers, and it will do what a motivated raccoon in an archive does: inspect labels, open boxes, and spend context figuring out where the answer might be.
This started with a familiar research impulse. Preparing material on late interaction, we collected a small pile of research papers. And of course, in this day and age of vibe coding, we wondered if we could make an agent prepare some sort of app based on these papers, rather than reading them directly.
The topic was efficient multi-vector retrieval. The rabbit hole started with the excellent awesome-multivector-retrieval repo, a very useful curated list of papers around ColBERT-style late interaction, MaxSim, vector pruning, token merging, and sparse lexical bridges. We were curious about all the other clever ways people try to keep the retrieval power of late interaction without storing half the universe as token embeddings.
So we downloaded 20 papers on the topic, built a small agent-facing corpus, and started asking broad comparison questions:
Compare the approaches that bridge late-interaction multi-vector retrieval with sparse lexical retrieval, contrasting how sparsity is induced and how inverted indexing is leveraged for scoring.
How do specialized indexing and kernel-level acceleration techniques for MaxSim compare to MUVERA's reduction-to-MIPS approach?
Of course this worked. It was also immediately annoying.
Twenty papers is a tiny corpus. A sufficiently motivated agent can list the directory, inspect filenames, open PDFs, and muddle through. But watching it work felt less like watching a scholar and more like watching something dropped into a dark archive with a flashlight: resourceful, determined, and very likely to start reading stuff on the wrong shelf.
Without search, the agent is not really using the library. It is foraging. Occasionally it is a very expensive raccoon in the stacks: energetic, technically exploring, and absolutely not what you want as your information architecture (yes, yes, we are assuming the raccoon is interested in late interaction).
That raised the question we could not leave alone:
At what point does "just let the agent read files" stop being cute and start being a tax?
So we turned the question into an experiment.
The Setup
We kept that initial small corpus first: 20 papers, 295 pages total, all about efficient late-interaction retrieval.
We ran the same Claude agent in two conditions:
- Native tools. Claude could ls the folder and Read PDF pages. Or grep, sure, but grep does not work on PDFs, so. The filenames were visible, like labels on shelves in a dark archive.
- LightOn tools. Claude could call LightOn search over the same pre-ingested corpus and retrieve the parsed Markdown, produced at ingestion, for a file when needed. LightOn acted like the catalogue and the librarian: it pointed Claude toward evidence, but Claude still had to synthesize.
The ingestion was done up front with the LightOn document APIs (and actually, also done by Claude using the LightOn API skill). Then we asked 20 broad research questions, drafted by AI and human-curated: some comparing different methods, some more exploratory, and got answers in both setups.
For quality, we used a blinded pairwise judge. Kimi K2.6 was given the question, a gold reference, Candidate A, and Candidate B, and chose which it preferred without knowing which answer came from which setup (a Chinese model judging an American model using French retrieval tools. Somewhere in there is a diplomatic incident, or at least a good eval pipeline).
What The Agent Actually Did
The native run looked like someone walking the aisles with a flashlight:
ls
ls # again, I guess our raccoon is wondering if the filenames changed
Read FLASH-MAXSIM pages 1-2
Read Sculpting pages 1-3
Read CRISP pages 1-3
Read CITADEL pages 1-3
...For one pruning question, it even opened FLASH-MAXSIM_fused_kernels.pdf early. For people who do not read papers on late interaction for a living: FLASH-MAXSIM is a great paper, but not the obvious first stop for "compare EMVB's per-document and per-query term filtering against learned token pruning, clustering, and merge-based reduction methods."
The LightOn run looked different. It asked the catalogue first:
lighton_search("EMVB per-document term filtering centroid late interaction")
lighton_search("learned token pruning ColBERT removing tokens")
lighton_search("token clustering merge reduction multi-vector embeddings")It got chunks from BitVectors_dense_retrieval.pdf, ColBERTer.pdf, Sculpting_prune_then_merge.pdf, CRISP_clustering_pruning.pdf, and friends on the first turn. Better than randomly opening some paper, right? Our little raccoon got a librarian telling it where the useful stuff is.
Search changed Claude's job from:
Walk the archive, find the evidence, then reason.
to:
Start with the books recommended by the librarian, reason over them, and ask for more material if need be.
That distinction becomes more important than the raw token number.
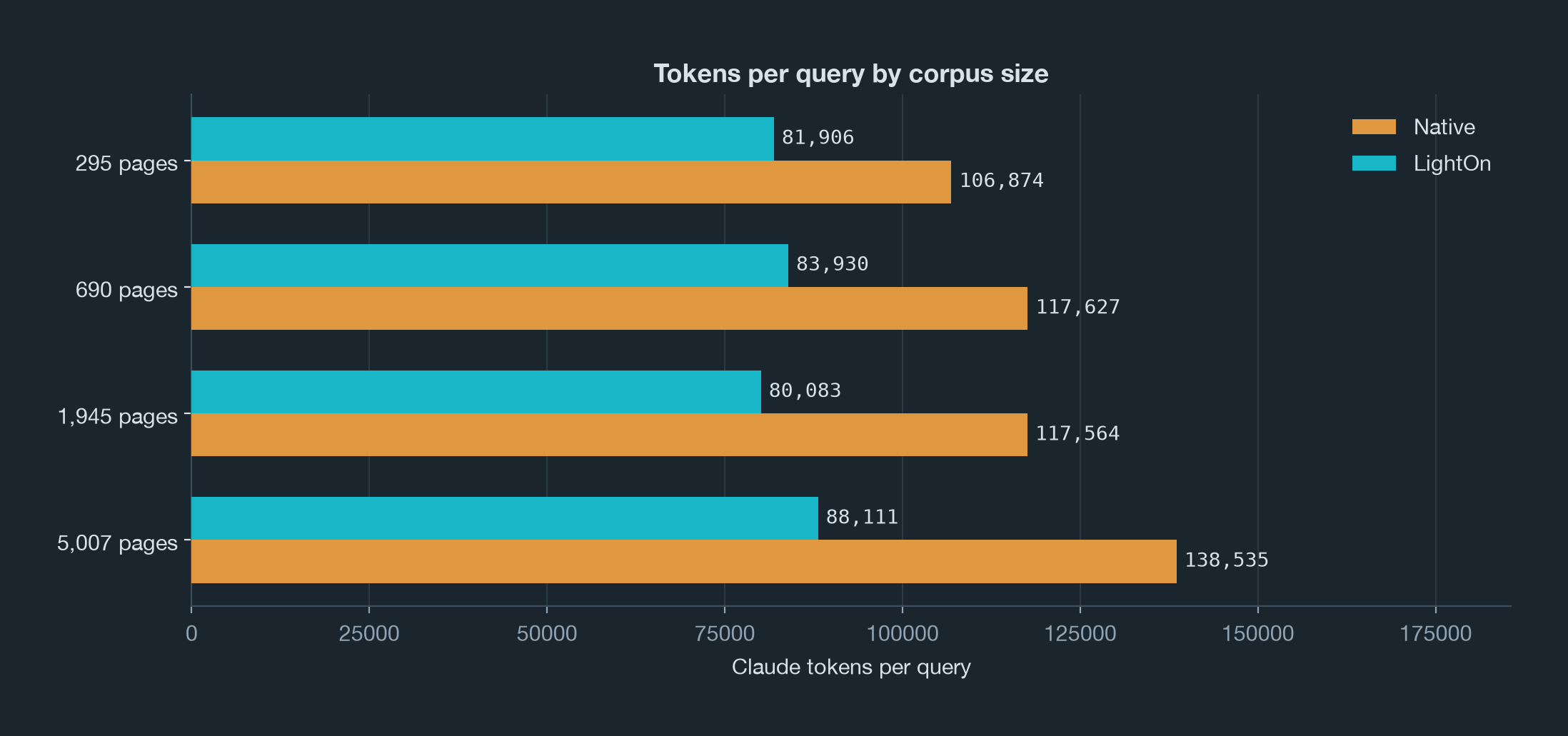
The First Result: Tiny Corpus, Still Fewer Tokens
The first run was almost unfair to LightOn. The descriptive filenames gave the native agent some pretty good shelf labels:
ColBERTv2_lightweight_late_interaction.pdf
Sculpting_prune_then_merge.pdf
MUVERA_fixed_dim_encodings.pdf
FLASH-MAXSIM_fused_kernels.pdfThis is not how customer document repositories usually look. If yours does, congratulations to your filing discipline, we are not all built the same. But shelf labels are still not a proper search system. They can suggest an aisle, not the paragraph with the answer.
Even in that friendly setup, search saved tokens without hurting judged quality.
We then made it more interesting by adding distractors to the runs. These were chosen carefully to be documents from roughly related domains. This matters: if you add random cooking recipes to a folder of retrieval papers, the benchmark is silly. The agent can ignore them by smell (badum tss). These distractors were closer to real enterprise clutter: long, serious, document-shaped things that can steal attention, tool calls, and context. In fact, one of these documents was the infamous "Attention Is All You Need" paper.
.png)
The ± values are bootstrap standard deviations: over paired query/repetition runs for token reduction, and over blinded pairwise judgments for judge win rate. We reran several settings multiple times to reduce run-to-run noise.
The important message is obvious. Enabling search let Claude use fewer tokens, and answer quality stayed consistent. More than that: at larger corpus sizes, search is essential to preserve answer quality. Which makes sense, because randomly foraging through a corpus makes it quite likely our raccoon will miss a crucial piece of information.
By around 5k pages, one native run hit the context wall:
prompt is too long: 1,166,002 tokens > 1,000,000 maximumThis is the moment where using search and wondering about "tokens saved" becomes the wrong framing. The stronger issue is feasibility. A raw context window is not a document database, and a bigger flashlight does not replace a librarian. Once the corpus is large enough, the direct-reading agent has three choices:
- miss evidence,
- open too much and drown in noise,
- rebuild retrieval badly inside the agent loop.
On the other hand, LightOn search kept the number of search calls almost flat:
.png)
The corpus grew about 17x in pages. Search stayed on point, and the token budget per query stayed roughly the same.
Why Quality Improved At Larger Size
We looked at the judge's reasons for the 5k-page run, because "search wins more" is not a satisfying explanation. As we said before, intuitively it makes sense: the more distractors there are, the more likely our agent is to get lost and miss a crucial piece of information. Checking the judge's comments on queries where the native setup lost, we found it complained that the agent:
- missed whole method families;
- misattributed a detail to the wrong paper (hello, context rot);
- made confident but unsupported quantitative claims;
- produced incomplete or truncated reasoning after reading too broadly;
- got distracted by a nearby-but-not-central paper.
When LightOn won, the reasons usually sounded like:
- it covered more of the gold reference;
- it separated key concepts more cleanly;
- it used more precise paper-specific details.
Retrieval powered by LightOn made Claude smarter. The agent got high-density chunks from multiple relevant papers instead of a pile of PDF pages selected by shelf-label vibes.
Or, in cruder terms: Claude is a better synthesizer than librarian. Stop making it cosplay as both.
The Naming Experiment, Or: Confusion Is Cheap
Then came the funniest results. We tried renaming the same 20 PDFs under different regimes:
- Descriptive titles: our baseline, where each document has a clear name that corresponds to the paper's main contribution, e.g. ColBERTv2_lightweight_late_interaction.pdf;
- Opaque arXiv IDs: the corresponding arXiv ID for each paper, e.g. 2112.01488.pdf for the ColBERTv2 paper;
- Mixed descriptive/IDs: half the papers' names replaced by the corresponding arXiv ID, half left descriptive.
As we said before, we think most people's data resembles this third condition: you bothered to rename some of your documents, then got lazy. Our intuition was that removing the labels from the shelves, so to speak, would make the agent explore much more and waste tokens.
.png)
At first glance, replacing titles with IDs made Claude more token-efficient. This is the kind of result that makes you question everything.
Analyzing some of the agent traces explained the behavior. With clean filenames, Claude used the directory listing as an index. It saw Sculpting_prune_then_merge.pdf, walked to that shelf, opened the box, read a lot, and kept going. It made Claude overly confident.
With opaque IDs, the shelf labels stopped helping. Claude made more tool calls but read fewer pages: it sampled, guessed, and moved on. Cheaper, yes, but not better. The native setup's win rate dropped.
Mixed titles were the most cursed: just enough semantic signal to lure the agent toward a plausible shelf, not enough to be a reliable catalogue. The judge's reasons in those runs mention fabricated methods, wrong attributions, and missing comparative elements.
So the lesson is not "rename your documents to IDs to save tokens." Please do not put that in a procurement slide.
The lesson is: filename intelligence is not retrieval. Shelf labels can help if they are accurate, but they are not a librarian.
From Experiment To Simulator
From there, we fitted a small scaling law from the measured page-count runs. The goal is not to pretend a toy curve can predict every run. It is to give a quick estimate of the basic shape: as the knowledge base grows, search keeps the agent's working set bounded while brute-force reading keeps asking the model to wander the archive. These estimates will feed a dedicated simulator, so people can quickly estimate how many tokens they would save by using a search tool on search-intensive workloads.
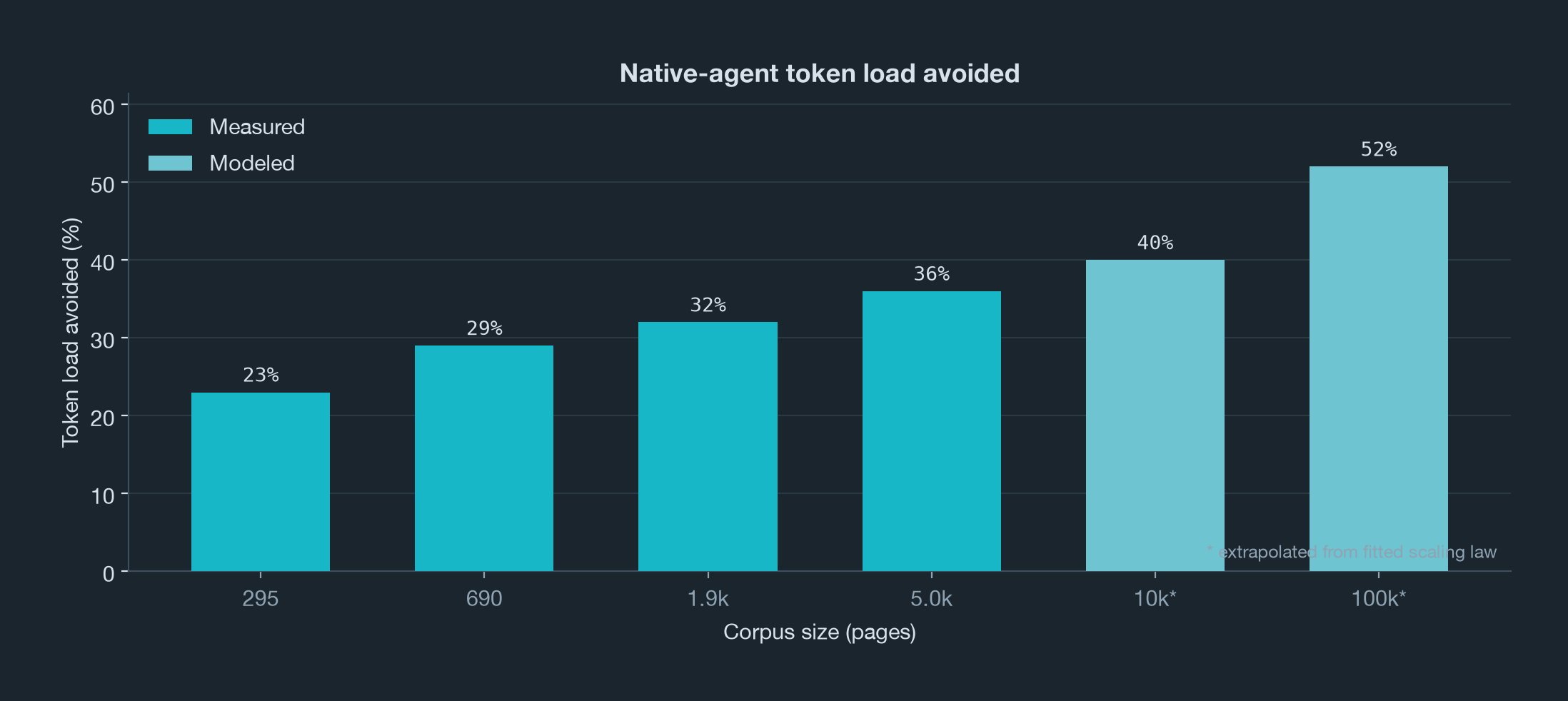
How To Read This
This is a deliberately small model, not a universal benchmark of Claude, LightOn, Kimi, or the moral worth of avoiding reading papers and making your agent rummage through them instead. The measured setup is narrow: one domain, one main agent model, one judge model, a small number of queries.
Its usefulness is in the lesson it teaches. Even on 295 pages, with unusually helpful filenames, with only one user interacting with the same knowledge base, search is already the right call on token load while preserving answer quality.
On that single-user point: this experiment is conservative, because it treats ingestion as a visible cost. But ingestion is paid once for a shared knowledge base. As soon as multiple users query the same corpus, or the same users query it repeatedly, the ingestion cost amortizes away very quickly. The agent-token waste, on the other hand, comes back every time the raccoon starts foraging.
The Takeaway
As information retrieval researchers, we are used to measuring search with recall, precision, and everyone's favorite, NDCG. These metrics ask familiar questions: did we retrieve the relevant documents? Did we pick up trash alongside them? Did we rank the best evidence first?
In the agent era, there is another metric hiding in plain sight: how expensive was it for the agent to find the evidence before it could even start answering? How many shelves did it inspect? How many boxes did it open? How many tokens did we spend on the flashlight tour?
As we discussed in our article on controlling token costs, token prices may keep falling, but agents are very good at finding new reasons to spend them. Some of that is what makes agentic search useful: agents can reason about what they need, explore, reformulate, and ask follow-up subqueries. But if document access is only brute-force reading, exploration becomes wandering. You are paying the model to be both librarian and analyst.
Dedicated search splits the job cleanly: the retrieval layer narrows the archive, while the agent reasons over the evidence. And as we have seen, this matters even at small scale. At 295 pages, dedicated search saved roughly 23% of Claude tokens with equal judged quality. At 5,000 pages, it saved roughly 36%, and answers powered by LightOn search won 75% of blinded comparisons.
The lesson is not that agents need a bigger flashlight. A longer context window helps the raccoon see more shelves. It still does not tell it where the answer lives. What your agent needs is a dedicated librarian, so it gets to reason over evidence rather than waste time hunting for it.
Search is not a nice-to-have tool bolted onto an agent. For document intelligence, it is the catalogue that turns a dark archive into a library, and keeps the context window from becoming a very expensive raccoon expedition.



.avif)
.avif)
