.svg)

Blog
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
À la une
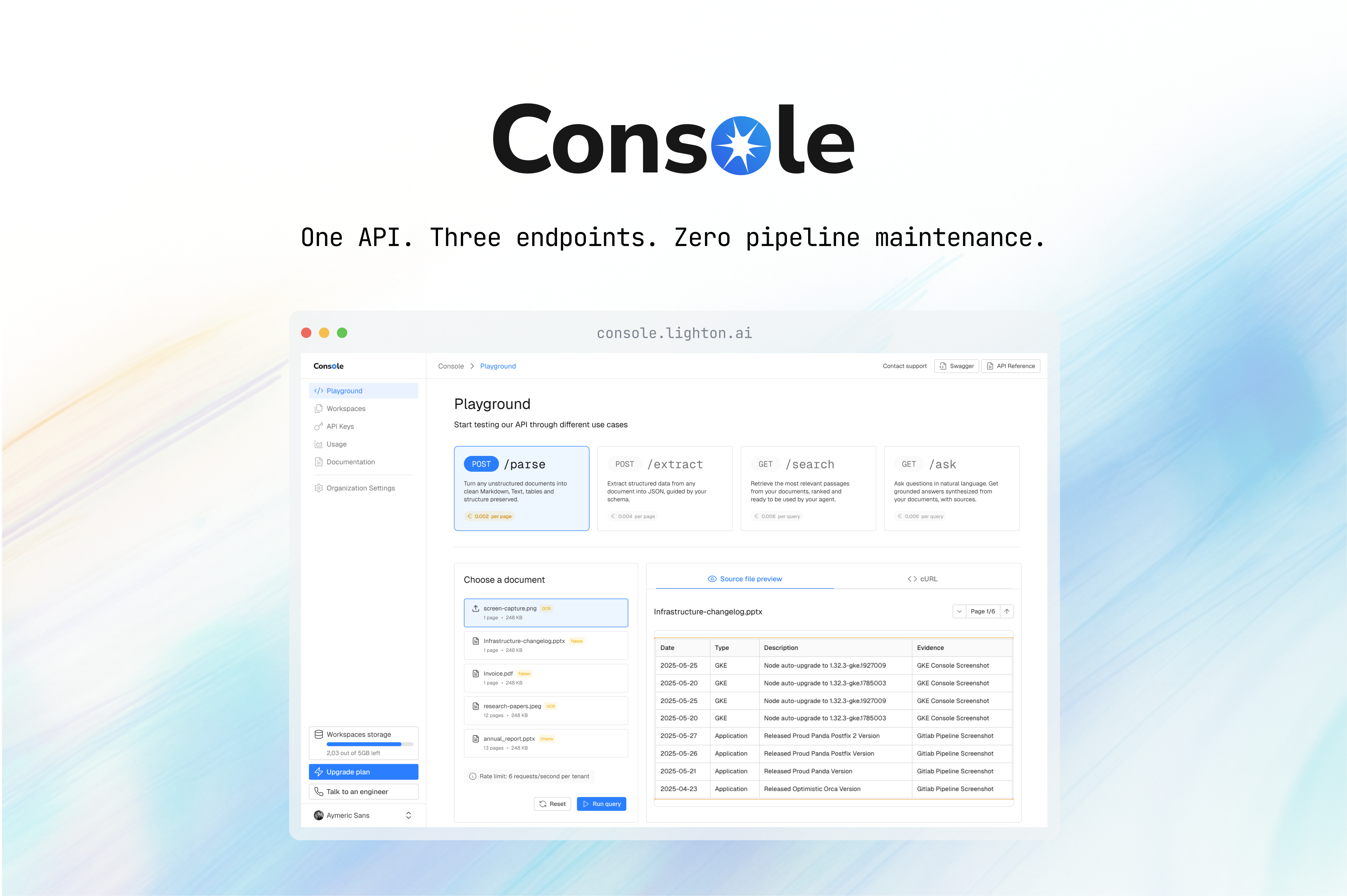
Découvrez LightOn Console
Un pipeline de retrieval pensé pour les agents. Un accès gratuit pour démarrer. Une API. Zero maintenance
June 2, 2026
Blog

Les systèmes critiques que votre audit cyber n’avait jamais vus
Un cas EDiTh sur la conformité NIS2 : LightOn identifie les systèmes OT réellement critiques à partir de documents incomplets, distribués et contradictoires.
May 26, 2026
Cas d'usage
CTA Title
Lorem Ipsum

L'ambiguïté d'une clause de force majeure, démêlée en un prompt
Les cas d’usage impossibles - Saison 1, épisode 02 : Juridique
May 22, 2026
Cas d'usage
CTA Title
Lorem Ipsum

LightOn rejoint le consortium AION porté par Ardian, Artefact, Bull, CapGemini, EDF, le Groupe iliad, Orange et Scaleway
Candidature pour une AI Gigafactory européenne en France
May 20, 2026
Blog
CTA Title
Lorem Ipsum

Adaptive Chunking: Reasoning Starts Before the LLM Sees a Token
Document-aware chunking selection for production RAG systems
May 19, 2026
R&D
CTA Title
Lorem Ipsum

Ces 825 000 € que vous avez sauvés avant le déjeuner
Le cas d’usage impossible
May 13, 2026
Cas d'usage
CTA Title
Lorem Ipsum

Votre pipeline RAG monopolise votre roadmap
Le gouffre du passage en production, le piège du retrieval, et comment en sortir.
April 24, 2026
Blog
CTA Title
Lorem Ipsum

🔴 The Retriever You Actually Need
Introducing LateOn and DenseOn, two Apache 2.0 retrievers: SOTA on BEIR, built to generalize.
April 21, 2026
R&D
CTA Title
Lorem Ipsum

No matching results found
We couldn’t find what you searched for. Try different keywords.