.svg)


TL;DR
L'IA spécialisée, appliquée aux documents, est aujourd'hui l'une des filières les plus en croissance du logiciel d'entreprise. Legal tech, achats, finance, construction : chaque secteur qui traite de gros volumes de documents non structurés est en train d'être reconstruit. Les équipes qui gagnent dans ces verticales ne gagnent pas sur la qualité du retrieval. Elles gagnent sur l'expertise métier, la distribution et la vitesse d'itération. Le retrieval est un prérequis, pas un facteur de différenciation. La vraie question est la suivante : quelle part de votre roadmap êtes-vous prêt à consacrer à une infrastructure qui ne constitue pas votre avantage concurrentiel.
Tous les produits IA finissent par heurter ce mur
Votre premier client enterprise vous envoie des contrats scannés de 2003, des tableaux Word avec des cellules fusionnées, des rapports bilingues, des annotations manuscrites sur des documents dactylographiés. Votre pipeline a été conçu pour des PDF numériques propres. Il produit des résultats médiocres.
Vous vous retrouvez avec quatre problèmes qui n'étaient pas sur votre roadmap six semaines plus tôt.
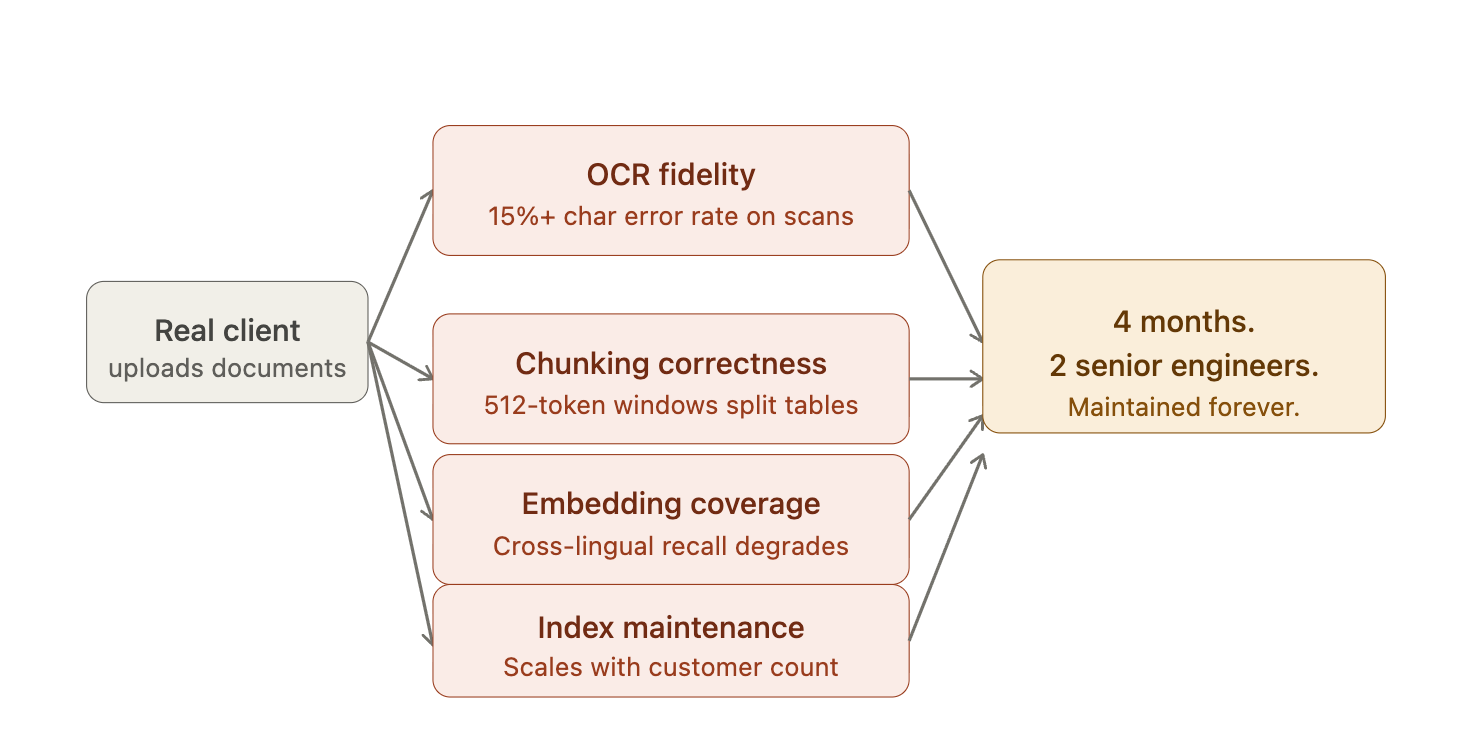
Précision OCR
Les wrappers Tesseract standard échouent dès que l'on sort du texte numérique propre. Des taux d'erreur de caractères supérieurs à 15 % sur des documents scannés se propagent directement sous forme de bruit dans le retrieval. Chaque caractère incorrect devient un mauvais token dans un mauvais embedding.
Correction du chunking
Le chunking à taille fixe détruit la structure des tableaux. Une fenêtre de 512 tokens coupe un tableau financier en pleine ligne. Le chunking sémantique sur des mises en page multi-colonnes produit des segments qui mélangent du contenu sans rapport provenant de colonnes adjacentes. Dans les deux cas, le recall se dégrade de manière difficile à diagnostiquer, car l'échec est silencieux : le système retourne des résultats, simplement les mauvais.
Couverture des embeddings
La plupart des modèles d'embedding en production ont été entraînés sur des corpus majoritairement anglophones. Les performances de retrieval cross-lingue chutent fortement pour les langues sous-représentées.
Maintenance de l'index
Chaque mise à jour de document nécessite un nouveau chunking, un nouvel embedding et des reconstructions partielles de l'index. Sans pipeline géré, cela devient une charge opérationnelle qui évolue avec le nombre de clients, et non avec votre capacité d'ingénierie.
Quatre mois. Deux ingénieurs seniors. Votre couche de retrieval est désormais plus complexe que votre produit lui-même, et elle devra être maintenue indéfiniment.
Les meilleures équipes passent au-dessus de ces problèmes.
Sur quoi vous êtes réellement en compétition
Demandez-vous ce qu'un concurrent ne peut pas copier.
L'expertise métier. La distribution. La compréhension du workflow de l'acheteur. L'intuition produit construite sur des dizaines d'appels commerciaux dans votre verticale.
Votre stratégie de chunking ne fait pas partie de cette liste. Ni votre logique de reranking, ni votre choix de modèle d'embedding, ni votre pipeline de parsing. Ce sont des problèmes d'infrastructure déjà résolus. Dès qu'ils sont correctement industrialisés, ils cessent d'être différenciants. C'est déjà le cas.
Trois endpoints
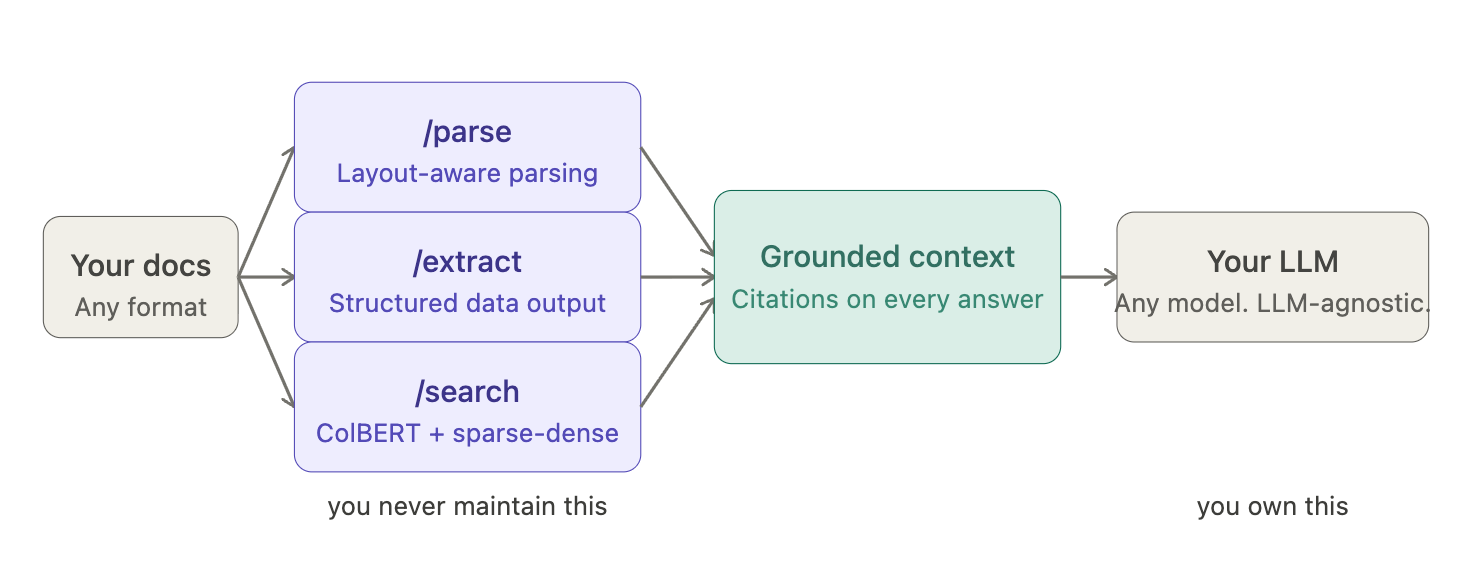
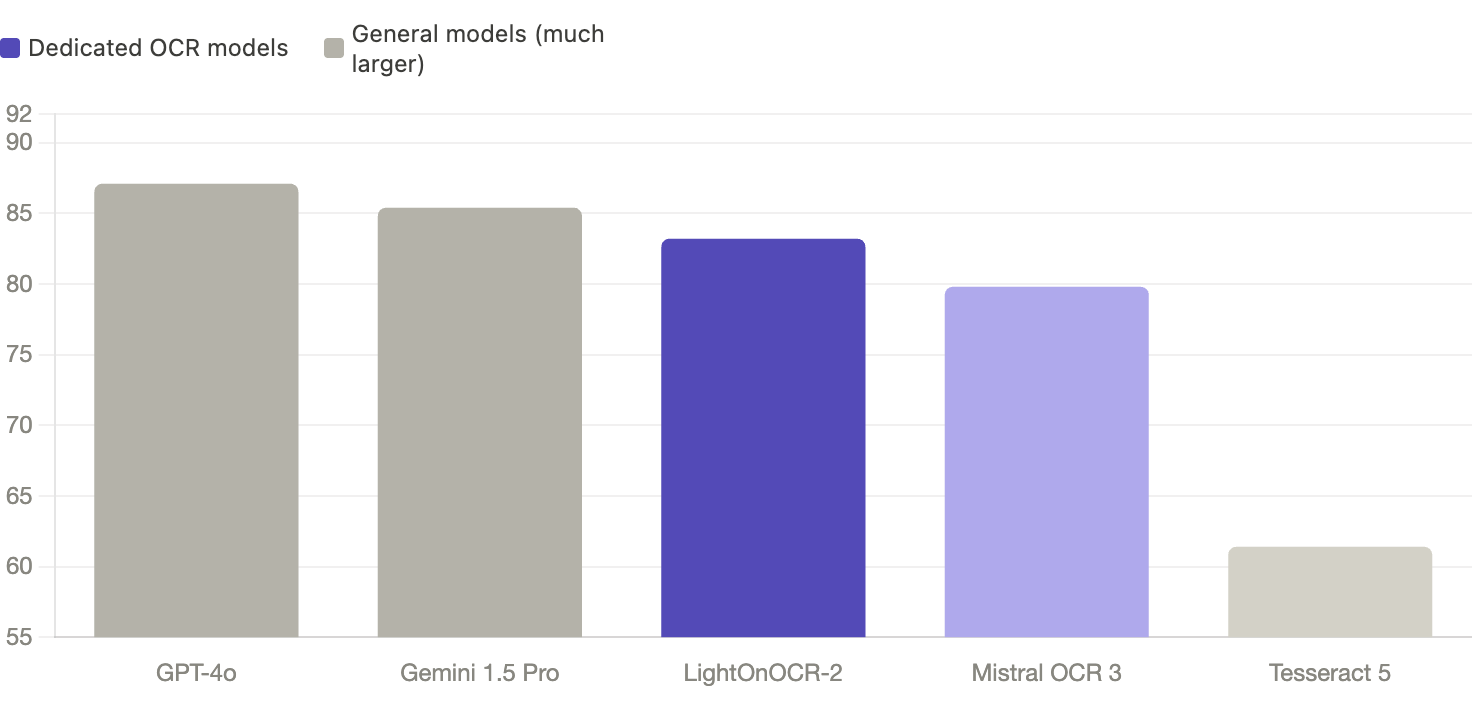
/parse exécute LightOnOCR-2. Score de 83,2 sur OlmOCR-Bench, premier parmi les modèles OCR dédiés et troisième au classement général derrière des modèles neuf fois plus volumineux.
Le parsing orienté mise en page gère nativement les documents multi-colonnes, les tableaux, l'écriture manuscrite et plus de 20 langues. Le parser préserve le graphe de mise en page au lieu d'aplatir le contenu en texte brut, ce qui permet au chunking en aval de s'appuyer sur de la structure plutôt que sur du bruit.
/extract retourne des données structurées à partir de documents qui n'ont jamais été conçus pour être lus par une machine. Cellules fusionnées, montants cachés dans des notes de bas de page, clauses réparties sur plusieurs pages : les décisions d'extraction sont prises avec le contexte complet de la mise en page, et non à partir d'un flux de texte aplati.
/search repose sur un retrieval à interaction tardive construit sur l'architecture ColBERT, combiné à un index hybride sparse-dense. Le matching au niveau des tokens, plutôt qu'une approximation par vecteur unique, permet de conserver une haute précision sur les documents longs et la terminologie spécifique aux domaines. Trente publications, onze docteurs, 45 millions de téléchargements de modèles sur Hugging Face. Les signaux sémantiques, lexicaux et visuels sont combinés, avec des citations de sources pour chaque réponse.
L'API est facturée à la requête, disponible en SaaS ou on-premise selon vos exigences de souveraineté des données, et isole les workspaces pour les produits multi-tenant. L'intégration prend quelques jours. La maintenance de l'index ne mobilise aucun ingénieur.
L'équipe dont vous avez besoin
Deux ingénieurs capables d'appeler une API et de lire une documentation. Pas d'équipe dédiée au retrieval, pas de backlog infrastructure. Les ressources qui auraient été consacrées aux pipelines de parsing restent focalisées sur le problème métier : la connaissance verticale, les intégrations dans les workflows et les décisions produit qu'un concurrent ne peut pas reconstituer à partir de votre historique de mises à jour.
C'est cela, le véritable avantage concurrentiel.
Découvrez àquoi ressemble le pipeline sous forme d'API : http://lighton.ai/api



.avif)
.avif)