.svg)


TL;DR
A new training method teaches models to reason over long documents by selecting and structuring relevant information. The resulting model, OriOn-Qwen-SR1, achieves state-of-the-art performance on MMLongBenchDoc (58.3) while remaining token-efficient and production-ready. Its key innovation is internalized reasoning: the model learns an explicit reasoning process during training but executes it implicitly at inference. No verbose output, no added latency.
RAG is the backbone of enterprise document intelligence, and we've long argued for it. But some tasks genuinely require a holistic view of a document: summarizing a 200-page report, cross-referencing information across sections, answering questions that depend on context scattered over dozens of pages. For these, chunking, embedding and retrieving isn't enough. You need a model that can reason over the full document.
With OriOn-Qwen-SR1, LightOn brings this long-context reasoning to a 32B model that outperforms models 7x its size on document understanding.
How the pipeline works
OriOn-Qwen-SR1 builds on our previous long context work by introducing a two-stage synthetic reasoning pipeline.
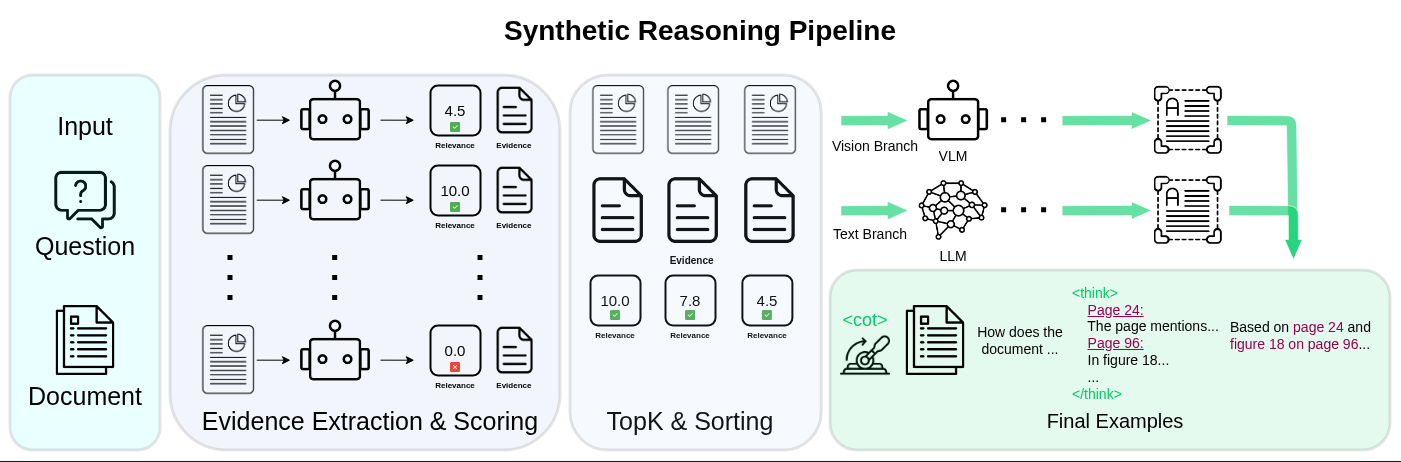
Stage 1: Evidence extraction and scoring. Each page is processed independently by a vision-language model, which extracts a relevant piece of evidence and assigns it a relevance score between 0 and 10. Pages used to generate the question are prompted to score between 6 and 10, ensuring ground-truth pages are consistently surfaced. Pages below the threshold are discarded, and the rest are ranked so that only the top-K (16 pages) are retained.
This filtering step is critical for the model to effectively learn a RAG-like retrieval algorithm within the provided long context, ensuring it can distinguish noise from relevant information.
Stage 2: Dual-branch answer generation. From the filtered evidence, a stronger teacher model (Qwen3 235B) generates training answers through two branches. The vision branch receives the top-ranked page images and the question, preserving layout, charts, and figures. The text branch receives only the extracted evidence snippets and the question, with no page images, forcing a causal link between the reasoning trace and the answer. Training examples are drawn equally from both branches, each pairing the document, question, reasoning trace, and final answer.
Internalized reasoning
During training, a <cot> control token in the system prompt gates whether the model sees the reasoning trace (95% on, 5% off). This teaches the model two modes: reason explicitly over the evidence, or answer directly.
The interesting part happens at inference. Through low-strength model merging, the explicit reasoning behavior is compressed into the model's weights. The merged model no longer emits <think> blocks, and its output length stays comparable to a non-reasoning baseline. But the <cot> token still works as a switch: including it at inference improves performance by +3.6 MMLBD for Qwen and +4.5 VA for Mistral, even though no visible reasoning is produced. Removing it degrades quality. The reasoning is still there, just internalized.
This changes the cost-performance trade-off. Traditional reasoning models improve accuracy at the cost of longer outputs and higher latency. OriOn-Qwen-SR1 delivers comparable gains at roughly the same token budget as a non-reasoning model.
Performance
Model accuracy on the official MMLongBenchDoc leaderboard.
OriOn-Qwen-SR1 reaches 58.3 on MMLongBenchDoc, surpassing Qwen3 VL 235B A22B (57.0) with 7× fewer parameters. The method also transfers to Mistral Small 3.1 24B with consistent gains, confirming it is not architecture-specific. For enterprise deployments, the efficiency profile matters as much as the score: smaller models are easier to run, more cost-efficient, and when they outperform larger systems on targeted benchmarks, the case for deployment becomes straightforward.
Why it matters for enterprise AI
Long-document understanding sits at the core of many enterprise workflows: legal analysis, financial reporting, compliance, research, internal knowledge retrieval. What these tasks require is not just language understanding but structured reasoning over distributed information, and that reasoning needs to start earlier in the pipeline than most current systems allow.
OriOn-Qwen-SR1 addresses this by focusing on relevance rather than raw context, keeping inference efficient through internalized reasoning, and exposing a simple control mechanism for production use.
Get Started
Read the paper: 📄 arxiv.org/abs/2604.02371
Download the model: 🤗 huggingface.co/lightonai/OriOn-Qwen-SR1
Whether you're building document intelligence pipelines, processing long-form contracts, or running RAG over hundreds of internal documents, LightOn gives you the infrastructure to move from prototype to production without compromise. Ready to see what enterprise-grade document AI looks like? Start here!



.avif)
.avif)