.svg)


TL;DR
Most RAG pipelines still apply one static chunking strategy across heterogeneous corpora. Adaptive Chunking: Optimizing Chunking-Method Selection for RAG introduces a framework that evaluates chunking strategies through five intrinsic, document-level metrics and dynamically selects the right one for each document. No LLM-as-a-judge. No end-to-end retrieval evaluation. Measurable retrieval gains, without changing the retriever, the embeddings, or the model behind them.
Most RAG Failures Start Before Retrieval
Most retrieval systems get optimized downstream. While embedding models get benched, rerankers get tuned and generation quality gets tweaked, chunking sits frozen upstream as a single static decision applied across entire corpora. Chunking sits frozen upstream as a single static decision applied across the entire corpus.
Pipelines inherit the structure of the chunks they index.
A broken table becomes a broken embedding. Fragmented references become fragmented retrieval. Oversized chunks dilute semantic precision. Aggressive splitting destroys context. By the time generation quality drops, the structural loss has already propagated through several layers.
This becomes visible the moment systems leave homogeneous datasets behind. Scientific papers, technical documentation, slide decks, large tables, contracts. None of them distribute information the same way. Most pipelines still force them through identical segmentation logic.
Adaptive Chunking starts from a simple observation. There is no universally optimal chunking strategy across heterogeneous document collections. The right question is not "what is the best chunker." It is "what is the best chunker for this document."
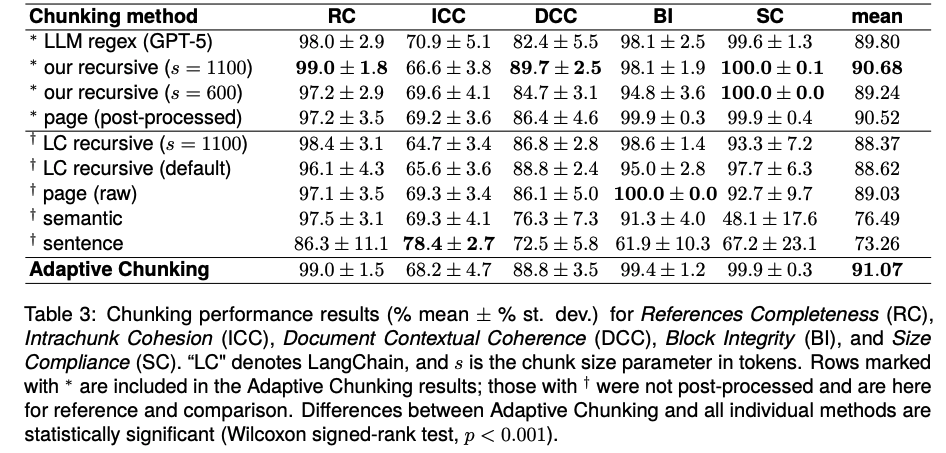
Five Metrics, No LLM Judge
Most chunking evaluation today depends on LLM-as-a-judge loops, manually labelledlabeled retrieval benchmarks, or downstream generation evaluation. All three are expensive and hard to operate at scale. Instead, Adaptive Chunking introduces a document-level selection framework. It evaluates multiple chunking strategies against five intrinsic metrics:
- References Completeness
- Intrachunk Cohesion
- Document Contextual Coherence
- Block Integrity
- Size Compliance
Together they capture complementary properties of chunk quality: semantic consistency, preservation of tables, lists, references, and section boundaries.
Intrinsic, document-level metrics keep the evaluation cheap enough to run inline in a real indexing pipeline. Chunking stops behaving like a one-shot text-splitting utility. It becomes an optimization layer in the pipeline itself.
Retrieval Gains Without Changing the Retriever
The paper evaluates several widely used chunking approaches alongside two newly proposed methods, and reports significant retrieval improvements compared to standard static pipelines.
Chunking Evaluation Results
Retrieval Evaluation Results

Two things matter here. First, the gains come entirely from better segmentation decisions upstream. The retriever and the embedding model do not change. Second, the cost of the evaluation framework itself stays low enough to run in production, not in a lab.
Why This Matters for the Cost of Your RAG Stack
The economics of retrieval in production are simple. LLM tokens cost money. The noisier the context shipped to the LLM, the more tokens burned for the same answer, and the more retries when the first one misses.
The cheap intuition is to fix this downstreams. Bigger model, longer context, better reranker. None of that addresses the root cause.
Reasoning can only be done on the information the LLM gets. It is impacted by the whole retrieval pipeline. Parsing depends on document layout. Chunking depends on coherence and boundaries. Indexing impacts what sits next to what.
When upstream reasoning is bad, the LLM tries to compensate. It re-queries, asks for clarifications, calls more tools, generates more output to cover gaps. For an agent looping through multiple retrieval-generation cycles per task, the compounding cost is brutal.
This is what LightOn is built for. LightOn is the retrieval engine for the agentic AI era. Every endpoint, /parse first among them, does part of the reasoning before the LLM is ever called. Chunking is selected at ingestion time based on document structure. Retrieved context is cleaner. Agents resolve queries in one pass instead of three. Each LLM call burns fewer tokens to produce a better answer.
Retrieval that costs less per query. Agents that burn fewer tokens per task. Not a bigger model thrown at the problem.
Links
Paper: https://huggingface.co/papers/2603.25333
Code: https://github.com/ekimetrics/adaptive-chunking
Try LightOn retrieval pipeline now:
- Sandbox /parse and /search in the LightOn Console: console.lighton.ai
- Read the API docs: docs.lighton.ai
- Talk to the team: contact us



.avif)
.avif)